¿Cuál es el gran problema con los clasificadores de instrumentos auditivos?
Introducción
Los instrumentos auditivos modernos proporcionan algún grado de cambio automático de programa basado en la clasificación acústica. Los más simples de estos dispositivos han estado disponibles casi desde el cambio de siglo, ¡y es difícil creer que hayan pasado 19 años desde entonces! ¿Alguna vez has considerado cómo el sistema de clasificación influye silenciosamente en el rendimiento de los instrumentos auditivos?
Si bien todavía hay algunas personas que desean controlar manualmente sus instrumentos auditivos, la mayoría preferiría ponérselos y olvidarse de ellos, permitiendo que los instrumentos auditivos se adapten automáticamente a sus cambiantes entornos de escucha. Eso coloca mucha responsabilidad en la precisión de la clasificación de la que ese dispositivo es capaz.
A medida que los instrumentos auditivos digitales se han vuelto más sofisticados, su rendimiento ha mejorado constantemente. Pero también ha aumentado la complejidad de los esquemas de clasificación acústica subyacentes que lo hacen posible. Con el lanzamiento de Indigo en 2005, Unitron introdujo un nuevo tipo de sistema de clasificación. Fue nuestro primer clasificador entrenado usando inteligencia artificial para distinguir entre cuatro escenas acústicas diferentes: escucha tranquila, habla en ruido, ruido y música.
Con la introducción de nuestro clasificador conversacional en la plataforma North, nos volvimos tan seguros de nuestra capacidad para clasificar correctamente siete entornos de escucha diferentes que usamos la salida del clasificador para impulsar Log It All, una primicia en la industria de Unitron. Si bien el registro de datos te dice lo que hace el instrumento auditivo a lo largo del tiempo, Log It All te dice cuánto tiempo pasa el usuario en cada uno de los siete entornos de escucha, mostrándote una visión general del estilo de vida auditivo del usuario y ayudándote a individualizar la experiencia del usuario en cada entorno. Sin embargo, para que Log It All tenga valor, debemos estar seguros de que el clasificador está categorizando con precisión estos entornos de escucha.
La clasificación es aún más importante para una buena experiencia de usuario. Puede configurar perfectamente los parámetros para cada entorno de escucha en el primer ajuste, pero si el clasificador que impulsa el cambio automático de programa detecta incorrectamente el entorno acústico, nada de eso importará. Por ejemplo, si el clasificador piensa que el usuario está escuchando música mientras en realidad está teniendo una conversación en un entorno tranquilo, el rendimiento del instrumento auditivo será inferior, porque está optimizado para el entorno de escucha incorrecto.
Por consiguiente, la clasificación precisa es un componente absolutamente crítico del éxito con los instrumentos auditivos modernos. En Unitron, queríamos saber: ¿lo hacemos bien? ¿Hemos entrenado nuestro clasificador para detectar con precisión los verdaderos entornos acústicos en los que los consumidores pasan su tiempo?
Para responder a nuestras preguntas, realizamos un estudio de evaluación comparativa de nuestro clasificador conversacional en la Universidad del Sur de Florida con el Dr. David Eddins y el Dr. Erol Ozmeral.
Qué hacen los clasificadores:
Los clasificadores automáticos muestrean el entorno acústico actual y generan probabilidades para cada uno de los destinos de escucha disponibles en el programa automático. El instrumento auditivo cambiará al programa de escucha para el cual se genera la mayor probabilidad. Cambiará nuevamente cuando el entorno acústico cambie lo suficiente como para que otro entorno de escucha genere una mayor probabilidad.
Sin embargo, no todos los esquemas de clasificación funcionan de la misma manera. Lo que los hace únicos es la filosofía de los ingenieros que los crean. Son estas filosofías las que impulsan sus elecciones sobre qué aspectos de un entorno acústico dado lo distinguen de todos los demás. Considera esto: los audífonos de dos fabricantes podrían estar expuestos al mismo entorno acústico y clasificarlo de manera diferente. ¿Por qué sucede esto? Es porque los diseñadores de los dos sistemas asignaron diferentes ponderaciones a los diversos aspectos de ese entorno acústico. Por lo tanto, los dispositivos estaban midiendo diferentes aspectos del entorno y tomando diferentes decisiones sobre los valores de lo que detectaron. Así, pueden llegar a diferentes conclusiones sobre el propio entorno acústico.
Por ejemplo, considere estos enfoques representativos para la clasificación acústica en instrumentos auditivos:
- (Kates, 1995) describió un sistema basado en el análisis de clúster de la modulación de envolvente y características espectrales para clasificar los ruidos de fondo en once clases: apartamento, murmullo, cena, platos, gaussiano, impresora, tráfico, escritura, hablante masculino, sirena y ventilación.
- (Nordqvist & Leijon, 2004) utilizaron modelos ocultos de Markov para desarrollar un sistema de clasificación robusto para instrumentos auditivos que contiene tres clases: habla en ruido de tráfico, habla en murmullo y habla limpia.
- (Büchler, Allegro, Launer, & Dillier, 2005) classified clean speech, speech in noise, noise and music using multiple approaches. Los autores explicaron muchos tipos de extracción de características y luego compararon seis clasificadores diferentes de baja a moderada complejidad, necesarios para el uso de HA.
- (Lamarche, Giguere, Gueaieb, Aboulnasr, & Othman, 2010) probaron dos sistemas: clasificadores de Distancia Mínima y Bayesianos. En cada caso, el clasificador puede adaptarse a los entornos únicos de los oyentes y ajustarse en consecuencia. Eligieron características distintivas que son buenas para distinguir entre entornos de Habla, Ruido y Música, incluyendo Profundidad de modulaciones de amplitud, Rangos de frecuencia de modulación (0 – 4 Hz & 4 – 16 Hz), y Varianza temporal de la frecuencia instantánea. Descubrieron que ambos métodos funcionaron bien. Pero tendían a fusionar las clases de manera diferente al reducir de tres clases a dos.
Aunque esta lista no es exhaustiva, muestra muchas de las aproximaciones disponibles para ingenieros y científicos que desarrollan estos algoritmos. Si bien las filosofías de las empresas de instrumentos auditivos son propietarias, aún es posible comparar estos esquemas entre sí y con un estándar de oro para evaluar lo que diferentes sistemas tienen para ofrecer. Con ese fin, desarrollamos un enfoque de evaluación basado en replicar entornos de escucha reales en un entorno controlado y repetible. El enfoque y algunos de los resultados se describirán en este documento.
El enfoque de evaluación comparativa:
Elegimos evaluar los clasificadores aplicando dos tipos de comparaciones. Primero, comparamos todos los clasificadores de instrumentos auditivos con un estándar de oro humano. En segundo lugar, comparamos los resultados del clasificador de los instrumentos auditivos de cinco fabricantes entre sí. Ambos enfoques ofrecen ideas útiles.
La ubicación
Realizamos todas las mediciones en el Laboratorio de Ciencias Auditivas & del Habla de la Universidad del Sur de Florida. La sala de sonido se muestra en la Figura 1.

Imagen 1
La silla en el centro de la habitación está rodeada por una serie de 64 altavoces a nivel de oído impulsados independientemente. Aunque la habitación es una cámara de prueba tratada acústicamente tradicional, se pueden montar paneles de plexiglás en las paredes y el techo para crear un entorno más naturalmente reverberante. Los participantes humanos están sentados en la silla en el centro de la habitación mientras evalúan los entornos de escucha. Obtuvimos datos de instrumentos auditivos en conjuntos de tres dispositivos a la vez utilizando un sistema antropomórfico Klangfinder (Figura 2).
Al reemplazar a los participantes humanos en el centro de la sala con el Klangfinder, fue posible repetir todas las condiciones de prueba para todos los sujetos y todos los instrumentos auditivos en un solo lugar.

Imagen 2
El Parkour Sonoro
Comenzamos el ejercicio de medición creando un parkour de sonido, una especie de curso de obstáculos acústico para poner a prueba a los clasificadores. Definimos el parkour en múltiples dimensiones, como se muestra a lo largo del encabezado y la columna izquierda de la Tabla 1. Cada fila de la Tabla 1 describe la composición de un único archivo de sonido que tiene una duración de dos minutos y representa un entorno de escucha específico. Esta iteración del parkour contiene 26 entornos de escucha (archivos de sonido). El entorno de escucha más simple se llama escucha tranquila (en la fila superior). No hay discurso, solo el suave sonido de un ventilador funcionando constantemente con un nivel general de 40 dB SPL. No hay casi ninguna modulación y ningún contraste temporal o espectral, solo un ruido suave y constante.
A medida que bajas por la tabla, los entornos de escucha se vuelven más complejos. Por ejemplo, en la columna de la izquierda verás que hemos añadido más hablantes y varios tipos diferentes de ruido de fondo. También experimentamos con diferentes niveles de música y ruido de fondo combinados con el habla en entornos muy complejos.
También hay un componente direccional en los elementos de habla, ruido y música. A medida que se añaden más altavoces, su orientación relativa al frente de los instrumentos auditivos se actualiza para reflejar dónde normalmente se pararía o se sentaría un altavoz en ese entorno. Este paso incorpora cualquier impacto del procesamiento direccional. Por ejemplo, observe la orientación de los altavoces: izquierda, derecha y frente, en el entorno del metro. Esta "distribución de hablantes" es lo que experimentarías en un andén del metro de Londres cuando estás sentado entre dos compañeros con otra persona frente a ti manteniendo una conversación. El componente direccional también se utiliza para el ruido y la música en los archivos de sonido. Se han utilizado múltiples iteraciones del parkour de sonido, de las cuales la Tabla 1 (descargar Tabla 1) es un ejemplo representativo.
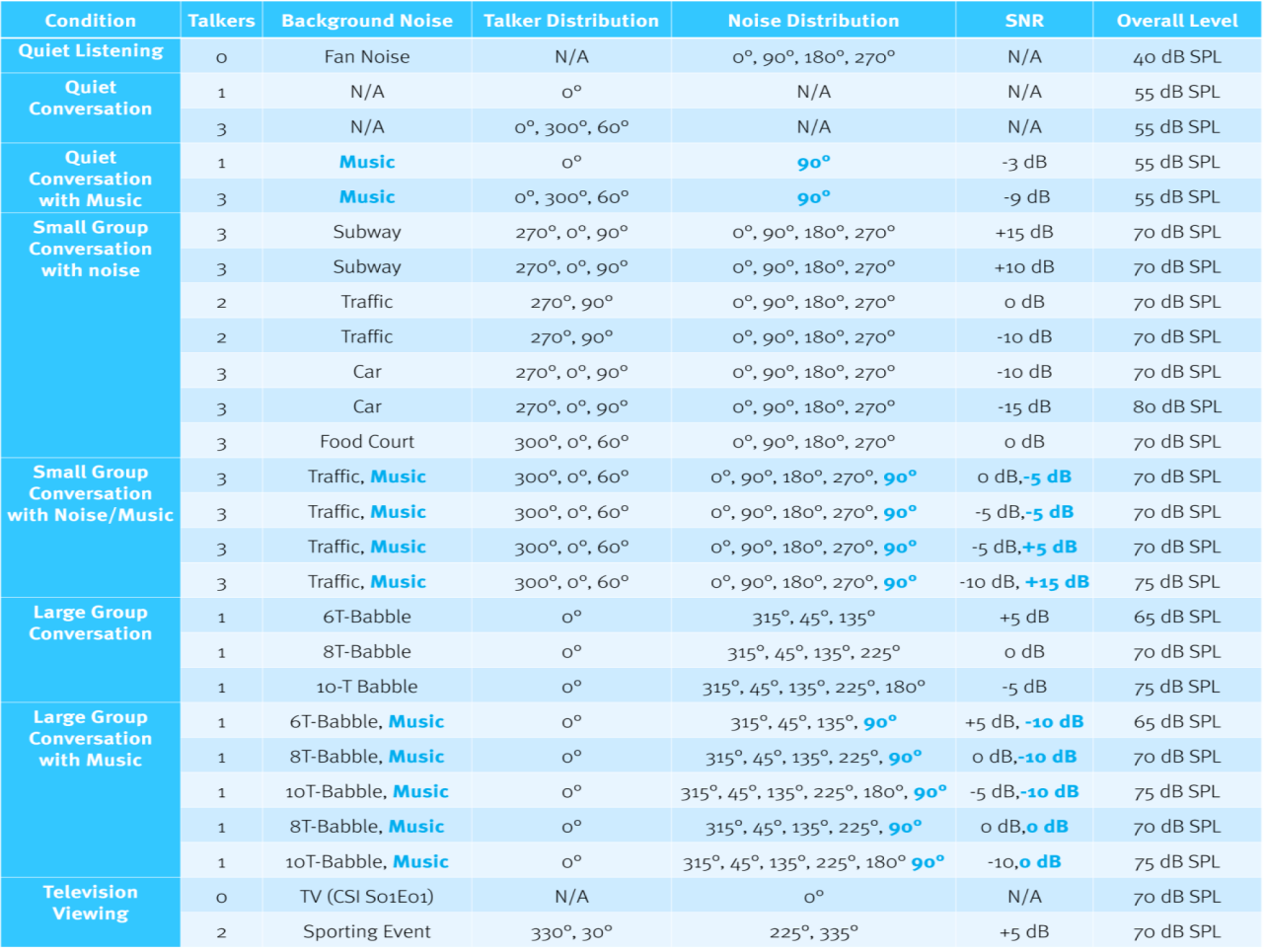
Tabla 1.
Cada archivo de sonido se repitió durante ocho horas de reproducción continua para cada conjunto de instrumentos auditivos en el Klangfinder. No había una forma directa de leer las probabilidades del clasificador desde la mayoría de los dispositivos. En su lugar, confiamos en los resultados de registro de datos durante ocho horas de un solo archivo para determinar cómo el clasificador de cada fabricante registró ese entorno de escucha particular. Dado que el registro de datos del tiempo pasado en un entorno de escucha determinado probablemente esté impulsado por las probabilidades del clasificador a lo largo del tiempo, repetir un único archivo de sonido durante ocho horas/sesión fue la forma más lógica de obtener resultados estables del clasificador.
¿Cómo se ven los resultados reales del clasificador?
Antes de observar los resultados obtenidos indirectamente de los instrumentos auditivos de cinco fabricantes utilizando la salida de registro de datos, será instructivo observar resultados más detallados de los instrumentos auditivos de Unitron. Es posible para Drs. Eddins y Ozmeral para leer las probabilidades del clasificador de nuestro instrumento auditivo instantáneamente varias veces por segundo mientras se generan. Las figuras 3 y 4 muestran las probabilidades reales del clasificador según lo determinado por un par de instrumentos auditivos Unitron utilizando este enfoque. El primer caso, Figura 3, muestra 60 segundos de probabilidades del clasificador para dos entornos de escucha muy simples.

Figura 3
En la parte superior de la Figura 3 podemos ver 60 segundos de la reproducción original. La primera mitad de esta figura muestra los últimos 30 segundos de la grabación del archivo WAV del entorno de ventilador suave (la fila superior de la Tabla 1). La segunda mitad muestra los primeros 30 segundos de la grabación de dos minutos del archivo WAV de la conversación tranquila con un solo hablante (segunda fila de la Tabla 1). Estos simples entornos de escucha demuestran cómo el clasificador genera probabilidades que casi exclusivamente representan un único entorno acústico de escucha.
El centro inferior de la figura está sincronizado con las grabaciones y muestra la distribución de probabilidades para cada uno de los siete posibles entornos de escucha en el clasificador de Unitron. Los primeros 30 segundos hay un 100% de probabilidad de que este sea un entorno de escucha tranquilo. Dado que es una grabación de un ventilador suave medido a solo 40 dB SPL en una habitación tratada acústicamente, esa clasificación es correcta. El instrumento auditivo pasaría estos 30 segundos en el entorno de escucha silencioso de SoundNav.
A los 30 segundos, la grabación cambia abruptamente del ventilador suave a 40 dB SPL a un solo hablante a 55 dB SPL. Desde 30 segundos hasta aproximadamente 37 segundos, las probabilidades del clasificador están en transición. Observe cómo la probabilidad de hablar en silencio comienza inmediatamente a aumentar a medida que la probabilidad de escuchar en silencio disminuye. Las dos probabilidades se cruzan aproximadamente a los 35 segundos. En esta zona de transición, SoundNav cambia el instrumento auditivo del entorno de escucha silencioso al entorno de escucha de habla en silencio. El clasificador detecta el cambio casi de inmediato, pero nuestros desarrolladores tomaron la decisión consciente de no hacer que el dispositivo reaccione demasiado rápido a cada pequeño cambio en el entorno acústico. Los cambios rápidos podrían llevar a una calidad de sonido reducida en entornos de escucha dinámicos mientras SoundNav intenta mantenerse al día con todas las fluctuaciones ambientales.
A los 40 segundos y durante los últimos 20 segundos de la grabación, la probabilidad de un discurso en un entorno de escucha silencioso es casi del 100%.
Las dos barras verticales a la izquierda y derecha de la sección de proporciones del clasificador muestran la proporción de tiempo dedicado a cada uno de los siete posibles entornos de escucha para el par de archivos WAV de dos minutos. La barra roja a la izquierda es el archivo WAV completo de dos minutos del ventilador suave, y la barra roja y azul a la derecha muestran la proporción de tiempo dedicado en cada uno de los siete entornos de escucha durante los dos minutos de discurso en el archivo WAV en silencio. La ligera sección roja representa el tiempo de transición al comienzo del discurso en la grabación silenciosa.
La Figura 4 es un ejemplo de lo que ocurre en un entorno de escucha más complejo.

Figura 4
Aquí podemos ver el impacto en las probabilidades de dos entornos de escucha mucho más complejos. En ambos casos, el oyente está conduciendo en el coche junto con tres hablantes. En el lado izquierdo (los primeros 30 segundos) el coche es mucho más silencioso con un nivel general de aproximadamente 70 dB y un SNR de -10 dB. Los niveles generales son mucho más difíciles en los segundos 30 segundos a un nivel de señal general de 80 dB con -15 dB SNR. Estos niveles pueden parecer SNR casi imposibles para un usuario de audífonos, pero el ruido del coche es distintivo en que casi toda la energía está en las frecuencias muy bajas (por debajo de 1000 Hz). Como tal, las SNRs parecen extremas, pero casi todo el habla de alta frecuencia es claramente audible en ambos archivos WAV.
A medida que el coche cambia de velocidad y los hablantes comienzan y se detienen, las probabilidades del clasificador varían ampliamente en una mezcla de tres entornos de escucha diferentes. Durante los primeros 30 segundos más suaves, la mayor probabilidad es la de conversación en un grupo pequeño, con un promedio del 50% al 60%. Como cabría esperar, la conversación en ruido también se detecta, variando del 0% al 50%. La conversación en un grupo grande tiene una probabilidad más pequeña pero aún notable que ronda entre el 15% y el 20% durante todo el tiempo. Una vez que el nivel general sube y la relación señal/ruido empeora, el sonido del ruido del coche se vuelve predominante. A medida que el coche acelera, las probabilidades del clasificador cambian drásticamente hacia la conversación en un entorno ruidoso y la conversación en un grupo pequeño cae por debajo del 20%.
Tómate un momento para reflexionar sobre estos dos ejemplos. El primero es fácil. Habiendo comparado instrumentos auditivos de muchos fabricantes, está claro que todos reaccionarían de manera similar en ambos entornos de escucha mostrados en la Figura 3.
¿Pero qué pasa con los dos entornos en la Figura 4? Aquí es donde la filosofía juega un papel. Hay mucho sucediendo en estos entornos de escucha y los desarrolladores tienen que tomar algunas decisiones sobre qué hacer. Por ejemplo, ¿qué es más importante: eliminar el ruido del coche o mejorar el habla? ¿En qué punto el nivel general es demasiado alto y no vale la pena preocuparse por el discurso? ¿Esa decisión se basa en el nivel general o en la relación señal/ruido? El parkour de sonido está diseñado para observar todas esas posibilidades y descubrir qué elecciones relevantes se han hecho.
El estándar de oro:
La Tabla 1 enumera archivos de sonido que representan varios entornos generales de escucha que un usuario de audífonos podría encontrar en la vida real. ¿Cómo supimos que los archivos representaban con precisión los entornos de escucha designados? Tuvimos 17 oyentes con audición normal que definieron para nosotros qué entornos de escucha pensaban que estaban mejor representados por cada archivo de sonido. (Se aceptaban múltiples respuestas.) Los archivos de sonido se reprodujeron en orden aleatorio para nuestros oyentes. Escucharon cada archivo de sonido tres veces, y describieron el entorno para cada iteración de cada archivo de sonido. Luego agrupamos todas sus respuestas para compararlas con los clasificadores de instrumentos auditivos.
En la Tabla 2 vemos cómo las descripciones de nuestros oyentes humanos se compararon con los siete entornos de escucha en nuestro clasificador:

Tabla 2.
Aunque hubo cierta superposición en la terminología específica, hubo diferencias interesantes en la interpretación de lo que significaban esos nombres. Había tres nombres para los entornos de escucha utilizados tanto por los oyentes como por el clasificador: "silencio", "ruido" y "música". Sin embargo, la interpretación de cada término era a menudo bastante específica. “Tranquilo” fue utilizado muy infrecuentemente por nuestros oyentes y rara vez superó el 3% para cualquier entorno de escucha. Por ejemplo, el archivo de sonido del ventilador en la parte superior de la Tabla 1 recibió una probabilidad del 100% de "silencio" por nuestro clasificador, ya que el nivel general era solo de 40 dB SPL, pero nuestros oyentes lo llamaron "ruido" el 92% del tiempo. Curiosamente, nuestros oyentes solo nos dieron una probabilidad de "ruido" por encima del 27% en solo otros dos entornos de escucha, ambos bastante ruidosos. Los archivos de sonido realmente ruidosos contenían todos discurso y, por lo tanto, nuestros oyentes les dieron las mayores probabilidades de "discurso en ruido". Lo mismo ocurrió con el clasificador, excepto que hizo una distinción en función del tipo de ruido, ya sea múltiples hablantes de fondo o ruido de motor como trenes, coches o tráfico. Ni los oyentes ni el clasificador detectaron "música" muy a menudo, y solo cuando era mucho más fuerte que todo lo demás a su alrededor. Pero los oyentes sí ofrecieron una categoría distinta de "habla en música" mezclada con "habla en ruido" en siete entornos donde el clasificador detectó un "grupo grande" (que lo eran, pero el clasificador ignoró la música en favor de optimizar el habla).
Las principales distinciones entre los oyentes y el clasificador no eran tanto que estuvieran detectando cosas diferentes, sino que estaban priorizando diferentes aspectos de los archivos de sonido o haciendo distinciones ligeramente más precisas en algunos casos. Por ejemplo, uno podría argumentar fácilmente que un ventilador suave a 40 dB SPL es tanto silencioso como un ruido. Ambas son interpretaciones correctas del mismo entorno de escucha.
La comparación multiproducto:
Los siguientes resultados muestran cómo los productos premium de cinco fabricantes, incluido Unitron, clasifican varios entornos de escucha frente a nuestros jóvenes oyentes con audición normal. Este ejercicio no se trata de quién tiene razón o quién está equivocado, sino que es una oportunidad para ver cómo se comparan diferentes clasificadores. Los resultados mostraron que algunos instrumentos auditivos son mejores en la clasificación que otros, y las diferentes filosofías de las empresas tienden a revelarse.
Empecemos de nuevo con un ejemplo sencillo. La Figura 5 muestra cómo los oyentes jóvenes normales y los cinco instrumentos auditivos clasificaron a un solo hablante masculino desde el frente a 55 dB SPL.

Figura 5
Los diferentes fabricantes tienen diferentes esquemas de clasificación que utilizan diferentes nombres para los entornos de escucha que clasifican. Usando sus descripciones de para qué estaba destinado cada destino de escucha, agrupamos los títulos en cuatro categorías principales: silencio, habla en ruido, ruido y música (como se muestra en la leyenda de la Figura 5). Estas cuatro categorías generales aparecen en todos los instrumentos auditivos que probamos bajo un nombre u otro, pero utilizamos los nombres genéricos en nuestros resultados para mantener el anonimato de los fabricantes e instrumentos auditivos involucrados. Nuestros oyentes normales clasificaron este archivo de sonido como escucha tranquila aproximadamente el 98% del tiempo. Todos los cinco instrumentos auditivos hicieron lo mismo.
La Figura 6 es un poco más compleja que la Figura 5. Hay nuevamente un solo hablante directamente frente al oyente, pero el nivel general del archivo de sonido es ahora de 80 dB SPL con una SNR nominal de 0 dB. El ruido de fondo es un tren del metro en el metro de Londres, y los niveles variaron a medida que los trenes llegaban y partían.

Figura 6
Nuestros oyentes normales clasificaron este archivo como habla en ruido aproximadamente el 83% del tiempo. También dijeron que era ruido el 4% del tiempo y silencio el 10% del tiempo. Teniendo en cuenta las diferencias de nivel a medida que los trenes llegaban y se iban, es justo decir que Unitron y el Competidor D estaban más cerca de lo que los jóvenes oyentes con audición normal nos dijeron. El competidor A no estaba muy atrás, sin embargo, los competidores B & C eran muy diferentes.
Aquí es donde las diferencias en filosofía se exponen por primera vez. Si miramos al Competidor B, ese instrumento clasificó el entorno como solo ruido aproximadamente el 50% del tiempo. Está claro que nuestros oyentes normales están reportando el habla en ruido de manera bastante consistente. Por lo tanto, la relación señal/ruido debe ser razonable la mayor parte del tiempo. Sin embargo, a 80 dB el nivel general es bastante alto. Por lo tanto, estamos deduciendo que el Competidor B tiene una filosofía que es más sensible al nivel general que al SNR en este caso, como los otros cuatro instrumentos auditivos probados.
El fondo se vuelve aún más complejo en la Figura 7. Aquí los oyentes estaban evaluando a un solo hablante desde el frente en un fondo de una zona de comidas en el centro comercial cerca de la hora del almuerzo. El nivel general fue un poco más bajo a 70 dB SPL a un SNR de 0 dB. Este es un complejo trasfondo de docenas de personas llevando a cabo muchas conversaciones a la vez, así como el sonido de las cocinas sirviendo comida y personas pasando.

Figura 7
En este caso, nuestros oyentes con audición normal informan sobre un 47% de habla en ruido y aproximadamente un 50% solo ruido. El otro 3% era música. Esta vez, los resultados del clasificador varían ampliamente entre los fabricantes. Mientras que todos los clasificadores ofrecieron alguna combinación de habla en ruido y ruido, los porcentajes para los Competidores A & C fueron completamente opuestos a los de los Competidores B & D.
Este puede ser el ejemplo perfecto de diferencias filosóficas en lo que el científico de audición de Unitron, Leonard Cornelisse, llama "el punto de rendirse". Él define el punto de rendición como el nivel de señal y/o SNR donde el usuario del audífono "se rinde" al intentar seguir el discurso porque la situación se ha vuelto demasiado difícil. Por debajo del punto de rendición, el oyente trabajará para seguir lo que se está diciendo y lo reportará como un entorno de habla en ruido, esperando que el instrumento auditivo enfatice la claridad del habla. Pero una vez que se cruza el punto de rendición, el oyente informa que es demasiado difícil seguir el discurso o demasiado fuerte para escuchar cómodamente, y le gustaría que el instrumento auditivo enfatizara la comodidad sobre la claridad. Cada clasificador está diseñado para tomar esa decisión en algún momento, y es una decisión impulsada puramente por la acústica. (A menos que el oyente cambie a un programa manual para anularlo.)
La primera conclusión de la Figura 7 es que los Competidores A & C asumen un punto de abandono más alto que los Competidores B & D. Tanto Unitron como los oyentes normales han indicado que este entorno está bastante bien justo en la línea del punto de abandono con una división cercana al 50/50 entre el habla en ruido y el ruido. Este es quizás el ejemplo más sorprendente de la filosofía impactando el rendimiento. Dado que el punto de rendición para diferentes personas con discapacidad auditiva a menudo varía ampliamente, ¿quién puede decir cuál de estas empresas lo hará absolutamente bien para un oyente en particular?
El ejemplo final es para escuchar música. En la Figura 8, vemos los resultados de la música que se reproduce sola (sin otros sonidos de fondo) a un nivel de 65 dB SPL. Este no es un nivel alto para escuchar música y no replica una actuación en vivo. Más bien, está más cerca del nivel al que un usuario de audífonos puede escuchar música mientras cocina o lee un libro, pero un poco más alto que la música de fondo.

Figura 8
En este caso, los oyentes normales, Unitron, Competidor A y Competidor C indicaron que este era esencialmente un entorno de escucha de música pura. Los competidores B & D lo clasificaron de manera diferente al menos el 33% y el 20% del tiempo, respectivamente. La clasificación errónea más común en este caso fue para el habla en ruido, y este es el único caso donde ocurrió un error claro e indefendible. Confundir música con habla en ruido equivale a configurar un instrumento auditivo para exactamente el tipo de rendimiento opuesto al que preferirías. Es una práctica generalmente aceptada establecer un entorno musical para la reproducción de banda ancha ligeramente procesada. Pero el habla en ruido generalmente recibe una fuerte dosis de micrófonos direccionales y cancelación de ruido diseñada, entre otras cosas, para reducir la amplificación de baja frecuencia. Para ser justos, tal error no era común para los cinco clasificadores.
Resumen
La clasificación de escenas sonoras de los instrumentos auditivos es un tema que recibe muy poca atención. Sin embargo, es uno de los componentes más importantes de la arquitectura del instrumento. Funcionando silenciosamente en segundo plano, los clasificadores toman todas las decisiones sobre qué conjuntos de parámetros de procesamiento son los más válidos en cualquier entorno de escucha dado, y afectan en gran medida cómo escucha un usuario.
Las decisiones de clasificación se basan tanto en la filosofía como en la acústica. Como tal, no todos los clasificadores son iguales en todas las situaciones. La mayoría de las veces, particularmente en situaciones de escucha simples, casi todos los principales instrumentos auditivos convergerán en resultados altamente consistentes que corresponden con cómo un oyente con audición normal clasificaría el entorno. Pero una vez que el entorno de escucha se vuelve más complejo, las diferencias en la filosofía y, a veces, en el rendimiento se hacen evidentes.
Con SoundNav, un clasificador entrenado usando inteligencia artificial, los resultados de Unitron son altamente consistentes con los de nuestros jóvenes oyentes con audición normal.
Agradecimientos
Me gustaría agradecer la colaboración del Dr. Ozmeral y el Dr. Eddins que trabajaron codo a codo con nosotros para desarrollar este recorrido del sonido y a proceder con la recolección de datos en el laboratorio de la Universidad del Sur de Florida.
Referencias:
Büchler, M., Allegro, S., Launer, S., & Dillier, S. (2005). Clasificación de sonido en audífonos inspirada en el análisis de escenas auditivas.EURASIP Journal on Applied Signal Processing, 18, 2991–3002.
Kates, J. M. (1995). Classification of background noises for hearing-aid applications.J Acoust Soc Am, 97(1), 461-470.
Lamarche, L., Giguere, C., Gueaieb, W., Aboulnasr, T., & Othman, H. (2010). Adaptive environment classification system for hearing aids.J Acoust Soc Am, 127(5), 3124-3135. doi:10.1121/1.3365301
Nordqvist, P., & Leijon, A. (2004). An efficient robust sound classification algorithm for hearing aids.J Acoust Soc Am, 115(6), 3033-3041.
También podría interesarte
