O que são os classificadores dos aparelhos auditivos?
Introdução
Todos os aparelhos auditivos modernos oferecem algum grau de troca de programa automático com base na classificação acústica. As versões mais simples desses dispositivos estão disponíveis quase desde a virada do século; é difícil acreditar que já se passaram 19 anos! Você já considerou como o sistema de classificação influencia o desempenho do aparelho auditivo de forma quase imperceptível?
Embora ainda existam algumas pessoas que desejam controlar manualmente seus aparelhos auditivos, a maioria prefere colocá-los e esquecê-los, permitindo que os aparelhos auditivos se adaptem automaticamente aos seus ambientes auditivos em mudança. Isso coloca muita responsabilidade na precisão da classificação de que esse dispositivo é capaz.
À medida que os aparelhos auditivos digitais se tornam mais sofisticados, seu desempenho tem melhorado continuamente. Mas também aumentou a complexidade dos esquemas de classificação acústica subjacentes, que tornam tudo isso possível. Com o lançamento do Indigo em 2005, a Unitron introduziu um novo tipo de sistema de classificação. Foi o nosso primeiro classificador treinado usando inteligência artificial para distinguir entre quatro cenas acústicas diferentes: escuta silenciosa, fala em ruído, ruído e música.
Com a introdução do nosso classificador conversacional na plataforma North, ficamos tão confiantes em nossa capacidade de classificar corretamente sete diferentes ambientes de escuta que usamos a saída do classificador para acionar o Log It All, uma inovação da indústria da Unitron. Enquanto o registro de dados informa o que o aparelho auditivo está fazendo ao longo do tempo, o Log It All informa quanto tempo o usuário passa em cada um dos sete ambientes de escuta – mostrando uma visão geral do estilo de vida auditivo do usuário, ajudando a individualizar a experiência do usuário em cada ambiente. No entanto, para que o Log It All tenha valor, precisamos ter certeza de que o classificador está categorizando com precisão esses ambientes de escuta.
A classificação é muito importante para uma boa experiência do usuário. Você pode configurar perfeitamente os parâmetros para cada ambiente de escuta na primeira adaptação, mas se o classificador que controla a troca automática de programas detectar erroneamente o ambiente acústico, nada disso importará. Por exemplo, se o classificador pensa que o usuário está ouvindo música enquanto na verdade está tendo uma conversa em um ambiente silencioso, o desempenho do aparelho auditivo será inferior, porque está otimizado para o ambiente de escuta errado.
Consequentemente, a classificação precisa é um componente absolutamente crítico para o sucesso dos aparelhos auditivos modernos. Então, nos perguntamos: será que a Unitron está fazendo certo? Treinamos nosso classificador para detectar com precisão os verdadeiros ambientes acústicos nos quais os consumidores passam seu tempo?
Para responder às nossas perguntas, realizamos um estudo de benchmarking do nosso classificador conversacional na Universidade do Sul da Flórida com o Dr. David Eddins e o Dr. Erol Ozmeral.
O que os classificadores fazem:
Classificadores automáticos amostram o ambiente acústico atual e geram probabilidades para cada um dos destinos de escuta disponíveis no programa automático. O aparelho auditivo mudará para o programa de audição para o qual é gerada a maior probabilidade. Ele mudará novamente quando o ambiente acústico mudar o suficiente para que outro ambiente de escuta gere uma probabilidade maior.
No entanto, nem todos os esquemas de classificação funcionam da mesma maneira. O que os torna únicos é a filosofia dos engenheiros que os criam. São essas filosofias que orientam suas escolhas sobre quais aspectos de um determinado ambiente acústico o distinguem de todos os outros. Considere esta situação: aparelhos auditivos de dois fabricantes diferentes podem ser expostos ao mesmo ambiente acústico e classificá-lo de forma diferente. Por que isso acontece? É porque os designers dos dois sistemas atribuíram pesos diferentes aos vários aspectos desse ambiente acústico. Portanto, os dispositivos medem aspectos diferentes do ambiente e tomam decisões diferentes sobre os valores detectados. Portanto, eles podem chegar a conclusões diferentes sobre o ambiente acústico em si.
Por exemplo, considere estas abordagens representativas para a classificação acústica em aparelhos auditivos:
- (Kates, 1995) descreveu um sistema baseado na análise de cluster da modulação do envelope e características espectrais para classificar ruídos de fundo em onze classes: apartamento, conversa, jantar, louça, gaussiano, impressora, tráfego, digitação, falante masculino, sirene e ventilação.
- (Nordqvist & Leijon, 2004) usaram modelos ocultos de Markov para desenvolver um sistema de classificação robusto para aparelhos auditivos contendo três classes: fala em ruído de tráfego, fala em murmúrio e fala limpa.
- (Büchler, Allegro, Launer, & Dillier, 2005) classificaram fala limpa, fala em ruído, ruído e música usando várias abordagens. Os autores explicaram muitos tipos de extração de características e então compararam seis classificadores diferentes de baixa a moderada complexidade, necessários para o uso de HA.
- (Lamarche, Giguere, Gueaieb, Aboulnasr e Othman, 2010) testaram dois sistemas: distância mínima e classificadores Bayesianos. Em cada caso, o classificador pode se adaptar aos ambientes exclusivos dos ouvintes e se ajustar de acordo. Eles escolheram características distintas que são boas para distinguir ambientes de fala, ruído e música, incluindo profundidade de modulação de amplitude, faixas de frequência de modulação (0–4 Hz e 4–16 Hz) e variação temporal da frequência instantânea. Eles descobriram que os dois métodos funcionavam bem. Mas eles tendiam a mesclar classes de maneira diferente quando mesclavam duas classes de três.
Embora esta lista não seja exaustiva, ela mostra muitas das abordagens disponíveis para engenheiros e cientistas que desenvolvem esses algoritmos. Embora as filosofias das empresas de aparelhos auditivos sejam proprietárias, ainda é possível comparar esses esquemas entre si e com um padrão ouro para avaliar o que os sistemas diferentes têm a oferecer. Para esse fim, desenvolvemos uma abordagem de benchmarking baseada na replicação de ambientes reais de escuta em um ambiente controlado e repetível. A abordagem e alguns dos resultados são descritos mais adiante neste artigo.
A abordagem comparativa:
Escolhemos comparar os classificadores aplicando dois tipos de comparações. Primeiro, comparamos todos os classificadores de aparelhos auditivos com um padrão ouro humano. Depois, comparamos os resultados dos classificadores de aparelhos auditivos de cinco fabricantes entre si. Ambas as abordagens oferecem insights úteis.
Localização
Realizamos todas as medições no Auditory & Speech Sciences Laboratory da University of South Florida. A sala de som é mostrada na Figura 1.

Figura 1
A cadeira no centro da sala é cercada por uma matriz de 64 alto-falantes ao nível dos ouvidos, acionados de forma independente. Embora a sala seja uma câmara de teste convencional com tratamento acústico, painéis de plexiglass podem ser montados nas paredes e no teto para criar um ambiente mais reverberante. Os participantes humanos estão sentados na cadeira no centro da sala enquanto avaliam os ambientes de escuta. Os dados dos aparelhos auditivos foram obtidos em conjuntos de três aparelhos por vez, por meio de um sistema antropomórfico Klangfinder (Figura 2).
Ao substituir os participantes humanos no centro da sala pelo Klangfinder, foi possível repetir todas as condições de teste para todos os participantes e todos os aparelhos auditivos em um local.

Figura 2
O Som Parkour
Começamos o exercício de medição criando um parkour sonoro – uma espécie de percurso de obstáculos acústico para testar os classificadores. Definimos o parkour em múltiplas dimensões, conforme mostrado ao longo do cabeçalho e da coluna esquerda da Tabela 1. Cada linha da Tabela 1 descreve a composição de um único arquivo de som que tem dois minutos de duração e representa um ambiente de escuta específico. Esta iteração do parkour contém 26 ambientes de escuta (arquivos de som). O ambiente de escuta mais simples é chamado de escuta silenciosa (na linha superior). Não há fala, apenas o som suave de um ventilador funcionando continuamente com um nível geral de 40 dB SPL. Quase não há modulação, e nenhum contraste temporal ou espectral, apenas um ruído suave e constante.
À medida que você desce na tabela, os ambientes de escuta se tornam mais complexos. Por exemplo, na coluna da esquerda você verá que adicionamos mais falantes e vários tipos diferentes de ruído de fundo. Também experimentamos níveis diferentes de música e ruído de fundo combinados com fala em ambientes muito complexos.
Há também um componente direcional para os elementos de fala, ruído e música. À medida que mais locutores são adicionados, sua orientação em relação à frente dos aparelhos auditivos é atualizada para refletir onde um locutor normalmente estaria naquele ambiente. Esta etapa incorpora qualquer impacto do processamento direcional. Por exemplo, observe a orientação dos locutores: esquerda, direita e frontal no ambiente de metrô. Essa “distribuição de locutores” é o que você encontraria em uma plataforma de metrô, por exemplo, ao sentar-se entre duas pessoas com uma outra pessoa à sua frente conversando. O componente direcional também é usado para o ruído e a música nos arquivos de som. Múltiplas iterações do parkour sonoro foram usadas, das quais a Tabela 1 (download Tabela 1) é um exemplo representativo.
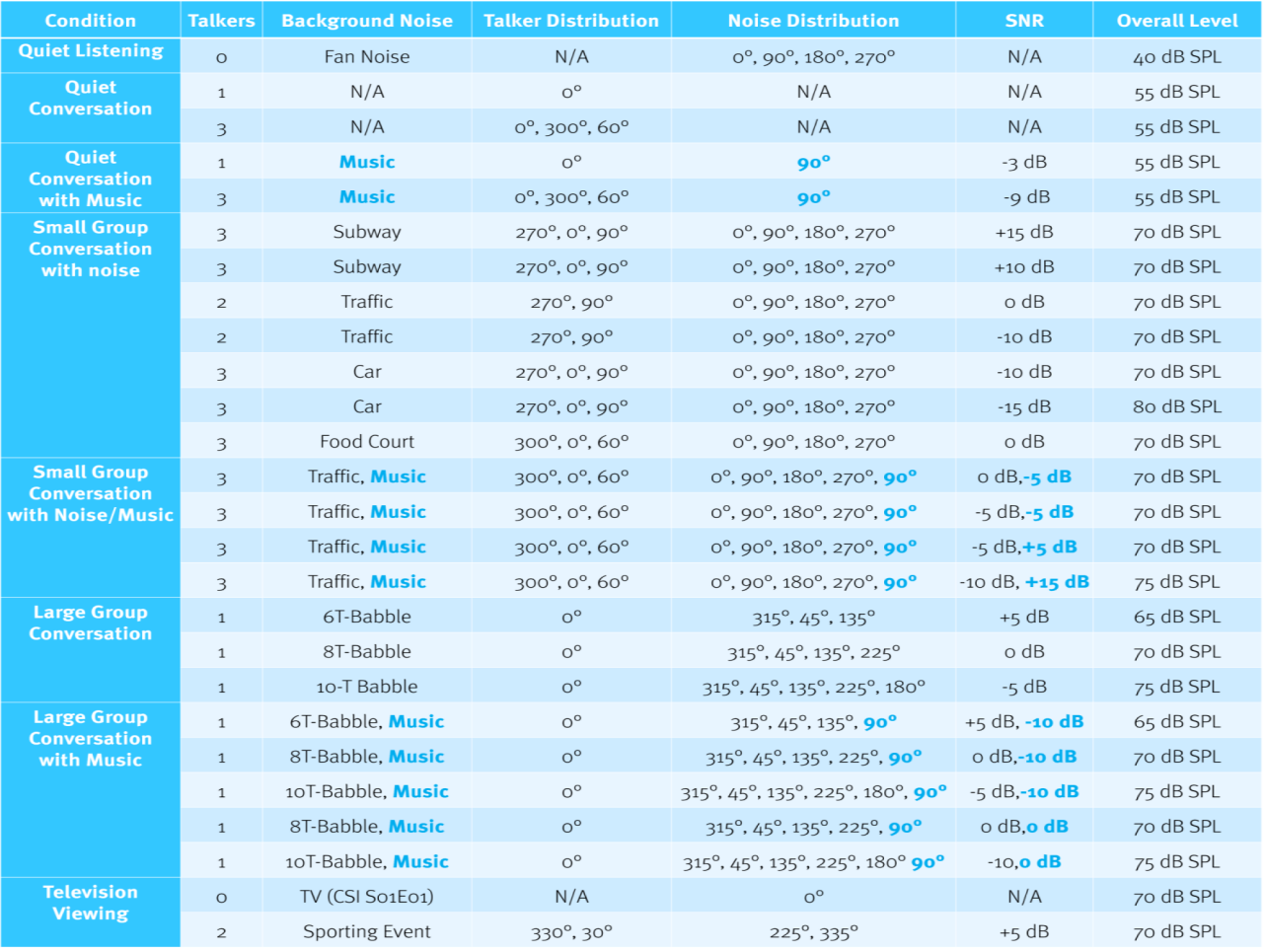
Tabela 1
Cada arquivo de som foi repetido por oito horas de reprodução contínua para cada conjunto de aparelhos auditivos no Klangfinder. Não havia uma maneira direta de ler as probabilidades do classificador da maioria dos dispositivos. Em vez disso, confiamos nos resultados do registro de dados de oito horas de um único arquivo para determinar como o classificador de cada fabricante registrou aquele ambiente de escuta específico. Dado que o registro de dados do tempo gasto em um determinado ambiente de escuta é provavelmente impulsionado pelas probabilidades do classificador ao longo do tempo, repetir um único arquivo de som por oito horas/sessão foi a maneira mais lógica de obter resultados estáveis do classificador.
Como são os resultados reais do classificador?
Antes de olhar para os resultados obtidos indiretamente de aparelhos auditivos de cinco fabricantes usando a saída de registro de dados, será instrutivo olhar para resultados mais detalhados de aparelhos auditivos da Unitron. É possível para Drs. Eddins e Ozmeral para ler as probabilidades do classificador do nosso instrumento auditivo instantaneamente várias vezes por segundo enquanto estão sendo geradas. As Figuras 3 e 4 mostram as probabilidades reais do classificador conforme determinado por um par de aparelhos auditivos Unitron usando esta abordagem. O primeiro caso, Figura 3, mostra 60 segundos de probabilidades do classificador para dois ambientes de escuta muito simples.

Figura 3
Na parte superior da Figura 3, é possível ver 60 segundos da reprodução original. A primeira metade desta figura mostra os 30 segundos finais da gravação do arquivo WAV do ambiente com ventilador suave (a linha superior da Tabela 1). A segunda metade mostra os primeiros 30 segundos da gravação de dois minutos do arquivo WAV da conversa tranquila com um único falante (segunda linha da Tabela 1). Esses ambientes de escuta simples demonstram como o classificador gera probabilidades que quase exclusivamente representam um único ambiente acústico de escuta.
O centro inferior da figura está sincronizado no tempo com as gravações e mostra a distribuição das probabilidades para cada um dos sete possíveis ambientes de escuta no classificador Unitron. Os primeiros 30 segundos têm 100% de probabilidade de que este seja um ambiente de escuta silencioso. Como se trata de uma gravação de um ventilador suave medido a apenas 40 dB SPL em uma sala com tratamento acústico, essa classificação está correta. O aparelho auditivo passaria esses 30 segundos no ambiente de escuta silenciosa do SoundNav.
Aos 30 segundos, a gravação muda abruptamente do ventilador suave a 40 dB SPL para um único falante a 55 dB SPL. De 30 segundos a aproximadamente 37 segundos, as probabilidades do classificador estão em transição. Observe como a probabilidade da fala no silêncio começa a aumentar imediatamente à medida que diminui a probabilidade da audição em silêncio. As duas probabilidades se cruzam em aproximadamente 35 segundos. Nesta zona de transição, o SoundNav muda o aparelho auditivo do ambiente de escuta silencioso para o ambiente de escuta de fala em silêncio. Na verdade, o classificador detecta a alteração quase imediatamente, mas nossos desenvolvedores tomaram a decisão consciente de não deixar o dispositivo reagir muito rápido a cada pequena alteração de ambiente acústico. Mudanças rápidas podem levar a uma qualidade de som reduzida em ambientes de escuta dinâmicos enquanto o SoundNav tenta acompanhar todas as flutuações ambientais.
Aos 40 segundos e nos últimos 20 segundos da gravação, a probabilidade de um discurso em um ambiente de escuta silencioso é quase 100%.
As duas barras verticais à esquerda e à direita da seção de proporções do classificador mostram a proporção de tempo gasto em cada um dos sete possíveis ambientes de escuta para o par de arquivos WAV de dois minutos. A barra vermelha à esquerda é o arquivo WAV completo de dois minutos do ventilador suave, e a barra vermelha e azul à direita mostram a proporção de tempo gasto em cada um dos sete ambientes de escuta durante os dois minutos de fala no arquivo WAV silencioso. A leve seção vermelha representa o tempo de transição no início da fala em gravação silenciosa.
A Figura 4 é um exemplo do que acontece em um ambiente de escuta mais complexo.

Figura 4
Aqui podemos ver o impacto nas probabilidades de dois ambientes de escuta muito mais complexos. Em ambos os casos, o ouvinte está dirigindo no carro junto com três falantes. No lado esquerdo (os primeiros 30 segundos), o carro está muito mais silencioso, com um nível geral de cerca de 70 dB e SNR de –10 dB. Os níveis gerais são muito mais difíceis nos 30 segundos, com um nível de sinal geral de 80 dB com SNR de –15 dB. Esses níveis podem parecer SNRs quase impossíveis para um usuário de aparelho auditivo, mas o ruído do carro é distinto porque quase toda a energia está nas frequências muito graves (abaixo de 1.000 Hz). Como tal, as SNRs parecem extremas, mas quase toda a fala de frequência aguda é claramente audível em ambos os arquivos WAV.
À medida que o carro muda de velocidade e os falantes começam e param, as probabilidades do classificador variam amplamente em uma mistura de três ambientes de escuta diferentes. Durante os primeiros 30 segundos mais suaves, a maior probabilidade é de conversa em um pequeno grupo, com média de 50% a 60%. Como você pode esperar, a conversa no ruído também é detectada, variando de 0% a 50%. A conversa em um grupo grande tem uma probabilidade menor, mas ainda perceptível, em torno de 15% a 20%. Quando o nível geral aumenta e a SNR piora, o som do ruído do carro se torna predominante. À medida que o carro acelera, as probabilidades do classificador mudam drasticamente para o ambiente de conversa em ruído e a conversa em um pequeno grupo cai abaixo de 20%.
Reserve um momento para refletir sobre esses dois exemplos. O primeiro é simples. Tendo comparado instrumentos auditivos de muitos fabricantes, é claro que todos reagiriam de forma semelhante em ambos os ambientes de escuta mostrados na Figura 3.
Mas e os dois ambientes da Figura 4? É aqui que a filosofia desempenha um diferencial. Há muita coisa acontecendo nesses ambientes de escuta e os desenvolvedores precisam tomar algumas decisões sobre o que fazer. Por exemplo, o que é mais importante: eliminar o ruído do carro ou melhorar a fala? Em que ponto o nível geral está muito alto e não vale a pena se preocupar com a fala? Essa decisão é baseada no nível geral ou na SNR? O parkour de sons foi desenvolvido para avaliar todas essas possibilidades e descobrir quais escolhas relevantes foram feitas.
O padrão ouro:
A Tabela 1 lista arquivos de som que representam vários ambientes gerais de escuta que um usuário de aparelho auditivo pode encontrar na vida real. Como sabíamos que os arquivos representavam com precisão os ambientes de escuta designados? Tivemos 17 ouvintes com audição normal que definiram para nós quais ambientes de escuta eles achavam que eram melhor representados por cada arquivo de som. (Respostas múltiplas eram aceitáveis.) Os arquivos de som foram reproduzidos em ordem aleatória aos ouvintes. Eles ouviram cada arquivo de som três vezes, e descreveram o ambiente para cada iteração de cada arquivo de som. Em seguida, reunimos todas suas respostas para comparar com os classificadores dos aparelhos auditivos.
Na Tabela 2 vemos como as descrições de nossos ouvintes humanos se comparam aos sete ambientes de escuta em nosso classificador:

Tabela 2
Embora houvesse alguma sobreposição na terminologia específica, havia diferenças interessantes na interpretação do que esses nomes significavam. Havia três nomes para ambientes de escuta usados tanto pelos ouvintes quanto pelo classificador: "silêncio", "ruído" e "música". No entanto, a interpretação de cada termo costumava ser bastante específica. "Quiet" foi usado muito raramente por nossos ouvintes e raramente excedeu 3% para qualquer ambiente de escuta. Por exemplo, o arquivo de som do ventilador na parte superior da Tabela 1 recebeu 100% de probabilidade de “silêncio” por nosso classificador, já que o nível geral era de apenas 40 dB SPL, mas os ouvintes o classificaram como “ruído” 92% das vezes. Curiosamente, nossos ouvintes só nos deram uma probabilidade de "ruído" acima de 27% em apenas dois outros ambientes de escuta, ambos bastante barulhentos. Todos os arquivos de som realmente barulhentos continham fala e, portanto, receberam as maiores probabilidades de “fala no ruído” pelos ouvintes. O mesmo era verdade para o classificador, exceto que ele fazia uma distinção com base no tipo de ruído, seja múltiplos falantes de fundo ou ruído de motor, como trens, carros ou tráfego. Nem os ouvintes nem o classificador detectaram “música” com muita frequência, e apenas quando o som era muito mais alto do que tudo ao seu redor. Mas os ouvintes ofereceram uma categoria distinta de “fala na música” misturada com “fala no ruído” em sete ambientes onde o classificador detectou um “grupo grande” (o que eram, mas o classificador ignorou a música em favor da otimização da fala).
As principais distinções entre os ouvintes e o classificador não foram tanto a diferença na detecção de coisas diferentes, mas sim a priorização de aspectos diferentes dos arquivos de som ou distinções um pouco mais precisas em alguns casos. Por exemplo, alguém poderia argumentar que um ventilador suave a 40 dB SPL é silencioso e barulhento ao mesmo tempo. Ambas são interpretações corretas do mesmo ambiente de escuta.
A comparação de multiprodutos:
Os seguintes resultados mostram como produtos premium de cinco fabricantes, incluindo a Unitron, classificam vários ambientes de escuta em comparação com nossos jovens ouvintes com audição normal. Este exercício não é sobre quem está certo ou quem está errado, é uma oportunidade de ver como os classificadores diferentes se comparam. Os resultados mostraram que alguns aparelhos auditivos são melhores na classificação do que outros, e as filosofias diferentes entre as empresas diferenciam os produtos.
Vamos começar novamente com um exemplo simples. A Figura 5 mostra como os jovens ouvintes normais e os cinco aparelhos auditivos classificaram um único falante masculino da frente a 55 dB SPL.

Figura 5
Diferentes fabricantes têm diferentes esquemas de classificação que usam nomes diferentes para os ambientes de escuta que classificam. Usando suas descrições de para que cada destino de escuta foi destinado, agrupamos os títulos em quatro categorias principais: silêncio, fala no ruído, ruído e música (conforme mostrado na legenda da Figura 5). Essas quatro categorias gerais aparecem em todos os aparelhos auditivos que testamos sob um nome ou outro, mas usamos os nomes genéricos em nossos resultados para manter o anonimato dos fabricantes e dos aparelhos auditivos envolvidos. Nossos ouvintes normais classificaram este arquivo de som como escuta silenciosa cerca de 98% do tempo. Todos os cinco aparelhos auditivos fizeram o mesmo.
A Figura 6 é um pouco mais complexa do que a Figura 5. Há novamente um único falante diretamente em frente ao ouvinte, mas o nível geral do arquivo de som agora é de 80 dB SPL com uma SNR nominal de 0 dB. O ruído de fundo é o de um trem do metrô, e os níveis variam conforme os trens chegam e partem.

Figura 6
Nossos ouvintes normais classificaram este arquivo como fala em ruído cerca de 83% do tempo. Eles também disseram que era ruído 4% das vezes e silêncio 10% das vezes. Levando em consideração as diferenças de nível conforme os trens chegam e partem, é justo afirmar que a Unitron e o Concorrente D foram os mais próximos do que os jovens com audição normal relataram. O Concorrente A não ficou muito atrás; no entanto, os Concorrentes B e C foram muito diferentes.
É aqui que as diferenças de filosofia são evidenciadas. Se analisarmos o Concorrente B, esse aparelho classificou o ambiente como apenas ruído cerca de 50% das vezes. É claro que nossos ouvintes normais estão relatando fala no ruído de forma bastante consistente. Portanto, a SNR deve ser razoável na maioria das vezes. No entanto, a 80 dB, o nível geral é muito alto. Portanto, inferimos que o Concorrente B possui uma filosofia mais sensível ao nível geral do que ao SNR neste caso, assim como os outros quatro aparelhos auditivos testados.
O fundo se torna ainda mais complexo na Figura 7. Aqui, os ouvintes estavam avaliando um único falante de frente em um fundo de praça de alimentação no shopping perto da hora do almoço. O nível geral foi um pouco mais baixo a 70 dB SPL a 0 dB SNR. Este é um cenário complexo de dezenas de pessoas em várias conversas ao mesmo tempo, bem como o som das cozinhas servindo comida e das pessoas passando.

Figura 7
Nesse caso, os jovens com audição normal relatam cerca de 47% de fala no ruído e cerca de 50% apenas ruído. Os outros 3%, música. Desta vez, os resultados do classificador variaram amplamente entre os fabricantes. Embora todos os classificadores tenham oferecido alguma combinação de fala no ruído e ruído, as porcentagens para os Concorrentes A e C foram completamente opostas às dos Concorrentes B e D.
Este pode ser o exemplo perfeito de diferenças filosóficas no que o Cientista de Audição da Unitron, Leonard Cornelisse, chama de "o ponto de desistência". Ele define o ponto de desistência como o nível do sinal e/ou SNR onde o usuário do aparelho auditivo “desiste” de tentar acompanhar a fala porque a situação se tornou muito difícil. Abaixo do ponto de desistência, o ouvinte faz um esforço para acompanhar o que está sendo dito e relata a situação como fala em ambiente com ruído, esperando que o aparelho auditivo enfatize a clareza da fala. Porém, após o ponto de desistência ser ultrapassado, o ouvinte relata que é muito difícil acompanhar a fala ou o som é muito alto para ouvir confortavelmente, e gostariam que o aparelho auditivo enfatizasse o conforto em vez da clareza. Cada classificador é desenvolvido para tomar essa decisão em algum ponto, e é uma decisão guiada puramente pela acústica. (A menos que o ouvinte mude para um programa manual para substituí-lo.)
A primeira conclusão da Figura 7 é que os Concorrentes A e C assumem um ponto de desistência mais alto do que os Concorrentes B e D. Tanto a Unitron quanto os ouvintes normais indicaram que esse ambiente está bem na linha do ponto de desistência, com cerca de 50/50 divididos entre fala no ruído e ruído. Esse talvez é o exemplo mais marcante da filosofia impactando o desempenho. Considerando que o ponto de desistência para diferentes pessoas com deficiência auditiva muitas vezes varia amplamente, quem pode dizer qual dessas empresas acertará absolutamente para um ouvinte específico?
O exemplo final é para ouvir música. Na Figura 8, vemos os resultados para música sozinha (sem outros sons de fundo) a um nível de 65 dB SPL. Esse não é um nível alto para ouvir música e não reproduz uma apresentação ao vivo. Em vez disso, está mais perto do nível em que o usuário de um aparelho auditivo pode ouvir música enquanto cozinha ou lê um livro, mas um pouco mais alto do que a música de fundo.

Figura 8
Neste caso, os ouvintes normais, Unitron, Concorrente A e Concorrente C indicaram que este era essencialmente um ambiente de escuta de música pura. Os concorrentes B e D o classificaram de forma diferente em pelo menos 33% e 20% das vezes, respectivamente. O erro de classificação mais comum nesse caso foi para fala no ruído, e esse é o caso em que ocorreu um erro claro e indefensável. Confundir música com fala no ruído é o mesmo que configurar um aparelho auditivo para o tipo de desempenho oposto ao que você deseja. É prática geralmente aceita definir um ambiente musical para reprodução levemente processada de banda larga. Porém, fala no ruído geralmente recebe uma grande dose de microfones direcionais e cancelamento de ruído projetado, entre outras coisas, para reduzir a amplificação de frequência grave. Para ser justo, essa falha não foi comum nos cinco classificadores.
Resumo
A classificação do cenário de som dos aparelhos auditivos é um tópico que recebe pouca atenção. No entanto, é um dos componentes mais importantes da construção do aparelho. Executando silenciosamente em segundo plano, os classificadores tomam todas as decisões sobre quais conjuntos de parâmetros de processamento são os mais válidos em qualquer ambiente de escuta, e impactam fortemente como um usuário ouve.
As decisões de classificação são baseadas tanto na filosofia quanto na acústica. Por isso, nem todos os classificadores são iguais em todas as situações. Na maioria das vezes, particularmente em situações simples de escuta, quase todos os principais aparelhos auditivos convergirão para resultados altamente consistentes que correspondem a como um ouvinte com audição normal classificaria o ambiente. Mas, uma vez que o ambiente de escuta se torna mais complexo, as diferenças na filosofia e, às vezes, no desempenho tornam-se óbvias.
Com o SoundNav, um classificador treinado usando inteligência artificial, os resultados da Unitron são altamente consistentes com os de nossos jovens ouvintes com audição normal.
Agradecimentos:
Gostaria de agradecer as contribuições do Dr. Ozmeral e do Dr. Eddins que trabalharam de perto conosco para desenvolver o parkour de sons e realizar a coleta de dados em seu laboratório na University of South Florida.
Referências:
Büchler, M., Allegro, S., Launer, S., & Dillier, S. (2005). Classificação de som em aparelhos auditivos inspirada na análise de cena auditiva.EURASIP Journal on Applied Signal Processing, 18, 2991–3002.
Kates, J. M. (1995). Classificação de ruídos de fundo para aplicações de aparelhos auditivos.J Acoust Soc Am, 97(1), 461–470.
Lamarche, L., Giguere, C., Gueaieb, W., Aboulnasr, T., & Othman, H. (2010). Sistema de classificação de ambiente adaptativo para aparelhos auditivos.J Acoust Soc Am, 127(5), 3124–3135. doi:10.1121/1.3365301
Nordqvist, P., & Leijon, A. (2004). Um algoritmo de classificação de som eficiente e robusto para aparelhos auditivos.J Acoust Soc Am, 115(6), 3033–3041.
Outros artigos interessantes
