Quel est le grand problème avec les classificateurs d'instruments auditifs ?
Introduction
Les appareils auditifs modernes offrent tous un certain degré de commutation automatique de programme basé sur la classification acoustique. Les plus simples de ces appareils sont disponibles depuis presque le tournant du siècle – et il est difficile de croire que cela fait 19 ans depuis! Avez-vous déjà envisagé comment le système de classification influence discrètement la performance des appareils auditifs ?
Bien qu'il y ait encore des personnes qui souhaitent contrôler manuellement leurs appareils auditifs, la plupart des gens préfèrent les mettre et les oublier, permettant ainsi aux appareils auditifs de s'adapter automatiquement à leurs environnements d'écoute changeants. Cela place beaucoup de responsabilité sur la précision de la classification dont cet appareil est capable.
À mesure que les appareils auditifs numériques sont devenus plus sophistiqués, leur performance s'est constamment améliorée. Mais la complexité des schémas de classification acoustique sous-jacents qui rendent tout cela possible a également augmenté. Avec le lancement d'Indigo en 2005, Unitron a introduit un nouveau type de système de classification. C'était notre premier classificateur entraîné à l'aide de l'intelligence artificielle pour distinguer entre quatre scènes acoustiques différentes : écoute silencieuse, parole dans le bruit, bruit et musique.
Avec l'introduction de notre classificateur conversationnel sur la plateforme North, nous sommes devenus si confiants dans notre capacité à classer correctement sept environnements d'écoute différents que nous utilisons la sortie du classificateur pour alimenter Log It All, une première dans l'industrie de Unitron. Bien que l'enregistrement de données vous indique ce que fait l'appareil auditif au fil du temps, Log It All vous indique combien de temps le porteur passe dans chacun des sept environnements d'écoute – vous montrant un aperçu du style de vie d'écoute du porteur, vous aidant à individualiser l'expérience du porteur dans chaque environnement. Cependant, pour que Log It All ait de la valeur, nous devons être certains que le classificateur catégorise avec précision ces environnements d'écoute.
La classification est encore plus importante pour une bonne expérience utilisateur. Vous pouvez parfaitement configurer les paramètres pour chaque environnement d'écoute dès le premier ajustement, mais si le classificateur qui pilote le changement automatique de programme détecte mal l'environnement acoustique, rien de tout cela n'aura d'importance. Par exemple, si le classificateur pense que le porteur écoute de la musique alors qu'il est en réalité en train d'avoir une conversation dans un environnement calme, la performance de l'appareil auditif sera inférieure, car il est optimisé pour le mauvais environnement d'écoute.
Par conséquent, une classification précise est un élément absolument critique du succès avec les instruments auditifs modernes. Chez Unitron, nous voulions savoir : est-ce que nous avons bien compris ? Avons-nous entraîné notre classificateur à détecter avec précision les véritables environnements acoustiques dans lesquels les consommateurs passent leur temps ?
Pour répondre à nos questions, nous avons entrepris une étude comparative de notre classificateur conversationnel à l'Université de Floride du Sud avec le Dr David Eddins et le Dr Erol Ozmeral.
Ce que font les classificateurs :
Les classificateurs automatiques échantillonnent l'environnement acoustique actuel et génèrent des probabilités pour chacune des destinations d'écoute disponibles dans le programme automatique. L'appareil auditif passera au programme d'écoute pour lequel la probabilité la plus élevée est générée. Il changera à nouveau lorsque l'environnement acoustique changera suffisamment pour qu'un autre environnement d'écoute génère une probabilité plus élevée.
Cependant, tous les systèmes de classification ne fonctionnent pas de la même manière. Ce qui les rend uniques, c'est la philosophie des ingénieurs qui les créent. Ce sont ces philosophies qui guident leurs choix quant aux aspects d'un environnement acoustique donné qui le distinguent de tous les autres. Considérez ceci : les instruments auditifs de deux fabricants pourraient être exposés au même environnement acoustique et le classer différemment. Pourquoi cela arrive-t-il? C’est parce que les concepteurs des deux systèmes ont attribué des pondérations différentes aux divers aspects de cet environnement acoustique. Par conséquent, les appareils mesuraient différents aspects de l'environnement et prenaient différentes décisions concernant les valeurs de ce qu'ils détectaient. Ainsi, ils peuvent tirer des conclusions différentes sur l'environnement acoustique lui-même.
Par exemple, considérez ces approches représentatives de la classification acoustique dans les instruments auditifs :
- (Kates, 1995) a décrit un système basé sur l'analyse en grappes de la modulation d'enveloppe et des caractéristiques spectrales pour classer les bruits de fond en onze catégories : appartement, bavardage, dîner, vaisselle, gaussien, imprimante, circulation, dactylographie, locuteur masculin, sirène et ventilation.
- (Nordqvist & Leijon, 2004) ont utilisé des modèles de Markov cachés pour développer un système de classification robuste pour les appareils auditifs contenant trois classes : parole dans le bruit de la circulation, parole dans le brouhaha, et parole claire.
- (Büchler, Allegro, Launer, & Dillier, 2005) ont classifié le discours clair, le discours dans le bruit, le bruit et la musique en utilisant plusieurs approches. Les auteurs ont expliqué de nombreux types d'extraction de caractéristiques, puis ont comparé six classificateurs différents de complexité faible à modérée, nécessaires pour l'utilisation de l'HA.
- (Lamarche, Giguere, Gueaieb, Aboulnasr, & Othman, 2010) ont testé deux systèmes : classificateurs de distance minimale et bayésiens. Dans chaque cas, le classificateur peut s'adapter aux environnements uniques des auditeurs et s'ajuster en conséquence. Ils ont choisi des caractéristiques distinctives qui sont bonnes pour distinguer entre les environnements de Parole, de Bruit et de Musique, y compris la Profondeur des modulations d'amplitude, les Plages de fréquences de modulation (0 – 4 Hz & 4 – 16 Hz), et la Variance temporelle de la fréquence instantanée. Ils ont constaté que les deux méthodes fonctionnaient bien. Mais ils avaient tendance à fusionner les classes différemment lorsqu'ils passaient de trois à deux classes.
Bien que cette liste ne soit pas exhaustive, elle montre bon nombre des approches disponibles pour les ingénieurs et les scientifiques qui développent ces algorithmes. Bien que les philosophies des entreprises d'instruments auditifs soient propriétaires, il est tout de même possible de comparer ces schémas entre eux et à une norme d'or pour évaluer ce que les différents systèmes ont à offrir. À cette fin, nous avons développé une approche de benchmarking basée sur la reproduction d'environnements d'écoute réels dans un cadre contrôlé et reproductible. L'approche et certains des résultats seront décrits dans cet article.
L'approche de benchmarking :
Nous avons choisi d'évaluer les classificateurs en appliquant deux types de comparaisons. Tout d'abord, nous avons comparé tous les classificateurs d'appareils auditifs à une norme d'or humaine. Deuxièmement, nous avons comparé les résultats du classificateur pour les instruments auditifs de cinq fabricants entre eux. Les deux approches offrent des perspectives utiles.
L'emplacement
Nous avons effectué toutes les mesures au Laboratoire des sciences auditives & de la parole de l'Université de Floride du Sud. La salle de son est montrée à la Figure 1.

Figure 1
La chaise au centre de la pièce est entourée d'une série de 64 haut-parleurs au niveau des oreilles, chacun étant piloté indépendamment. Bien que la pièce soit une chambre de test traditionnelle traitée acoustiquement, des panneaux de plexiglas peuvent être montés sur les murs et le plafond pour créer un environnement plus naturellement réverbérant. Les participants humains sont assis sur la chaise au centre de la pièce tout en évaluant les environnements d'écoute. Nous avons obtenu des données d'instruments auditifs par ensembles de trois appareils à la fois en utilisant un système anthropomorphique Klangfinder (Figure 2).
En remplaçant les participants humains au centre de la pièce par le Klangfinder, il a été possible de répéter toutes les conditions de test pour tous les sujets et tous les instruments auditifs en un seul endroit.

Figure 2
Le Sound Parkour
Nous avons commencé l'exercice de mesure en créant un parcours sonore – une sorte de parcours d'obstacles acoustiques pour mettre les classificateurs à l'épreuve. Nous avons défini le parkour dans plusieurs dimensions, comme indiqué le long de l'en-tête et de la colonne de gauche du Tableau 1. Chaque ligne du Tableau 1 décrit la composition d'un seul fichier audio d'une durée de deux minutes et représente un environnement d'écoute spécifique. Cette itération du parkour contient 26 environnements d'écoute (fichiers audio). Le milieu d'écoute le plus simple est appelé écoute silencieuse (dans la rangée du haut). Il n'y a pas de discours, juste le doux bruit d'un ventilateur fonctionnant régulièrement avec un niveau global de 40 dB SPL. Il n'y a presque pas de modulation et aucun contraste temporel ou spectral – juste un bruit doux et constant.
À mesure que vous descendez dans le tableau, les environnements d'écoute deviennent plus complexes. Par exemple, dans la colonne de gauche, vous verrez que nous avons ajouté plus de locuteurs et plusieurs types différents de bruit de fond. Nous avons également expérimenté avec différents niveaux de musique et de bruit de fond combinés avec la parole dans des environnements très complexes.
Il y a aussi un composant directionnel aux éléments de discours, de bruit et de musique. À mesure que d'autres haut-parleurs sont ajoutés, leur orientation par rapport à l'avant des appareils auditifs est mise à jour pour refléter l'endroit où un haut-parleur se tiendrait ou s'assiérait normalement dans cet environnement. Cette étape intègre tout impact du traitement directionnel. Par exemple, notez l'orientation des haut-parleurs – gauche, droite et avant – dans l'environnement du métro. Cette « distribution de parleurs » est ce que vous vivriez sur un quai de métro dans le métro de Londres en étant assis entre deux compagnons avec une autre personne devant vous en train de converser. Le composant directionnel est également utilisé pour le bruit et la musique dans les fichiers sonores. Plusieurs itérations du parkour sonore ont été utilisées, dont le Tableau 1 (télécharger Tableau 1) est un exemple représentatif.
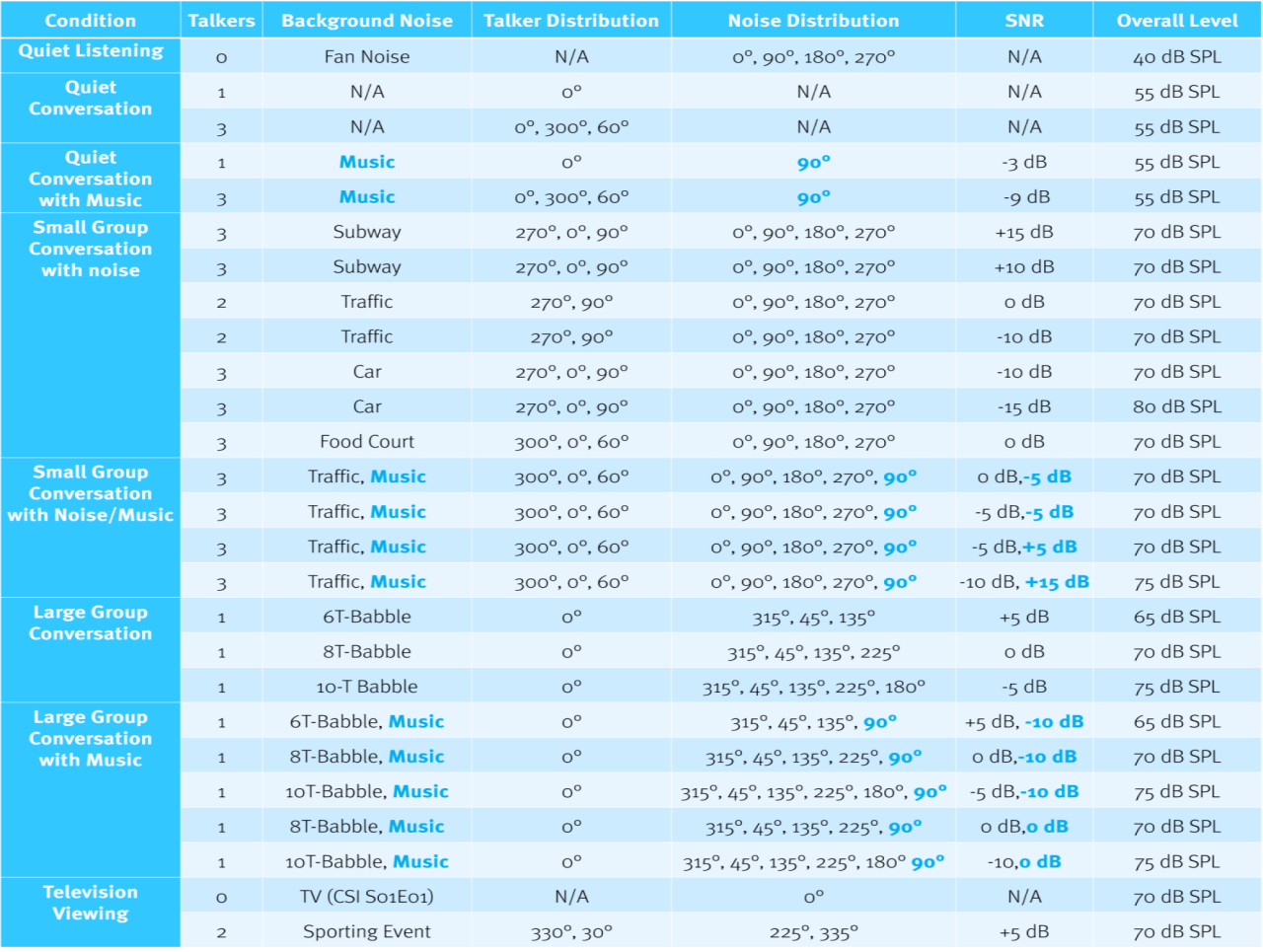
Tableau 1.
Chaque fichier sonore a été bouclé pendant huit heures de lecture continue pour chaque ensemble d'instruments auditifs dans le Klangfinder. Il n'y avait pas de moyen direct de lire les probabilités du classificateur à partir de la plupart des appareils. Au lieu de cela, nous nous sommes appuyés sur les résultats de l'enregistrement de données pendant huit heures d'un seul fichier pour déterminer comment le classificateur de chaque fabricant a enregistré cet environnement d'écoute particulier. Étant donné que la journalisation du temps passé dans un environnement d'écoute donné est très probablement motivée par les probabilités de classification au fil du temps, la boucle d'un seul fichier sonore pendant huit heures/session était la manière la plus logique d'obtenir des résultats de classification stables.
À quoi ressemblent les résultats réels du classificateur ?
Avant de regarder les résultats obtenus indirectement à partir des instruments auditifs de cinq fabricants en utilisant la sortie de journalisation des données, il sera instructif de regarder des résultats plus détaillés des instruments auditifs Unitron. Il est possible pour les Drs. Eddins et Ozmeral doivent lire les probabilités du classificateur de notre instrument auditif instantanément plusieurs fois par seconde pendant qu'elles sont générées. Les figures 3 et 4 montrent les probabilités réelles du classificateur telles que déterminées par une paire d'instruments auditifs Unitron utilisant cette approche. Le premier cas, Figure 3, montre 60 secondes de probabilités de classificateur pour deux environnements d'écoute très simples.

Figure 3
En haut de la figure 3, nous pouvons voir 60 secondes de la lecture originale. La première moitié de cette figure montre les 30 dernières secondes de l'enregistrement du fichier WAV de l'environnement de ventilateur doux (la première ligne du tableau 1). La deuxième moitié montre les 30 premières secondes de l'enregistrement de deux minutes du fichier WAV de la conversation calme avec un seul interlocuteur (deuxième ligne du tableau 1). Ces environnements d'écoute simples démontrent comment le classificateur génère des probabilités qui représentent presque exclusivement un seul environnement d'écoute acoustique.
Le centre inférieur de la figure est synchronisé avec les enregistrements et montre la distribution des probabilités pour chacun des sept environnements d'écoute possibles dans le classificateur Unitron. Les 30 premières secondes ont une probabilité de 100 % que ce soit un environnement d'écoute calme. Étant donné qu'il s'agit d'un enregistrement d'un ventilateur doux mesuré à seulement 40 dB SPL dans une pièce traitée acoustiquement, cette classification est correcte. L'instrument auditif passerait ces 30 secondes dans l'environnement d'écoute silencieux de SoundNav.
À 30 secondes, l'enregistrement passe brusquement du ventilateur doux à 40 dB SPL à un seul interlocuteur à 55 dB SPL. De 30 secondes à environ 37 secondes, les probabilités du classificateur sont en transition. Notez comment la probabilité de parler en silence commence immédiatement à augmenter alors que la probabilité d'écouter en silence diminue. Les deux probabilités se croisent à environ 35 secondes. Dans cette zone de transition, SoundNav passe l'appareil auditif de l'environnement d'écoute calme à l'environnement d'écoute de la parole en calme. Le classificateur détecte en fait le changement presque immédiatement, mais nos développeurs ont pris la décision consciente de ne pas faire réagir l'appareil trop rapidement à chaque petit changement dans l'environnement acoustique. Des changements rapides pourraient entraîner une réduction de la qualité sonore dans des environnements d'écoute dynamiques alors que SoundNav tente de suivre toutes les fluctuations environnementales.
À 40 secondes et pour les 20 dernières secondes de l'enregistrement, la probabilité d'un discours dans un environnement d'écoute silencieux est presque de 100%.
Les deux barres verticales à gauche et à droite de la section des proportions du classificateur montrent la proportion de temps passé dans chacun des sept environnements d'écoute possibles pour la paire de fichiers WAV de deux minutes. La barre rouge à gauche représente les deux minutes complètes du fichier WAV du ventilateur doux, et la barre rouge et bleue à droite montre la proportion de temps passé dans chacun des sept environnements d'écoute pendant les deux minutes de discours dans le fichier WAV silencieux. La légère section rouge représente le temps de transition au début du discours dans un enregistrement silencieux.
La figure 4 est un exemple de ce qui se passe dans un environnement d'écoute plus complexe.

Figure 4
Ici, nous pouvons voir l'impact sur les probabilités de deux environnements d'écoute beaucoup plus complexes. Dans les deux cas, l'auditeur conduit dans la voiture avec trois interlocuteurs. Du côté gauche (les 30 premières secondes), la voiture est beaucoup plus silencieuse avec un niveau global d'environ 70 dB et un SNR de -10 dB. Les niveaux globaux sont beaucoup plus difficiles dans les 30 secondes suivantes à un niveau de signal global de 80 dB avec un SNR de -15 dB. Ces niveaux peuvent sembler être des SNRs presque impossibles pour un porteur d'appareil auditif, mais le bruit de la voiture est distinctif en ce que presque toute l'énergie se trouve dans les très basses fréquences (en dessous de 1000 Hz). Ainsi, les SNR semblent extrêmes, mais presque toutes les fréquences élevées du discours sont clairement audibles dans les deux fichiers WAV.
Alors que la voiture change de vitesse et que les interlocuteurs commencent et arrêtent de parler, les probabilités du classificateur varient considérablement à travers un mélange de trois environnements d'écoute différents. Pendant les premières 30 secondes plus douces, la probabilité la plus élevée est celle de la conversation en petit groupe, avec une moyenne de 50 % à 60 %. Comme vous pourriez vous y attendre, la conversation dans le bruit est également détectée, variant de 0 % à 50 %. La conversation dans un grand groupe a une probabilité plus faible mais toujours notable, oscillant autour de 15 % à 20 % tout au long. Une fois que le niveau global augmente et que le SNR se détériore, le bruit de la voiture devient prédominant. Alors que la voiture accélère, les probabilités du classificateur basculent fortement dans l'environnement de conversation en bruit et la conversation en petit groupe tombe en dessous de 20%.
Prenez un moment pour réfléchir à ces deux exemples. Le premier est facile. Après avoir comparé les instruments auditifs de nombreux fabricants, il est clair que chacun réagirait de manière similaire dans les deux environnements d'écoute illustrés à la figure 3.
Mais qu'en est-il des deux environnements dans la Figure 4 ? C'est là que la philosophie joue un rôle. Il se passe beaucoup de choses dans ces environnements d'écoute et les développeurs doivent prendre certaines décisions sur ce qu'il faut faire. Par exemple, qu'est-ce qui est plus important : éliminer le bruit de la voiture ou améliorer la parole ? À quel moment le niveau global est-il trop fort et ne vaut-il pas la peine de s'inquiéter du discours ? Cette décision est-elle basée sur le niveau global ou le SNR? Le parkour sonore est conçu pour examiner toutes ces possibilités afin de découvrir les choix pertinents qui ont été faits.
Le standard d'or :
Le tableau 1 répertorie les fichiers audio qui représentent plusieurs environnements d'écoute généraux qu'un porteur d'appareil auditif pourrait rencontrer dans la vie réelle. Comment savions-nous que les fichiers représentaient fidèlement les environnements d'écoute désignés ? Nous avons eu 17 auditeurs à l'ouïe normale qui ont défini pour nous quels environnements d'écoute ils pensaient être les mieux représentés par chaque fichier sonore. (Plusieurs réponses étaient acceptables.) Les fichiers audio ont été joués dans un ordre aléatoire pour nos auditeurs. Ils ont entendu chaque fichier sonore trois fois, et ils ont décrit l'environnement pour chaque itération de chaque fichier sonore. Nous avons ensuite regroupé toutes leurs réponses pour les comparer aux classificateurs d'instruments auditifs.
Dans le tableau 2, nous voyons comment les descriptions de nos auditeurs humains se comparent aux sept environnements d'écoute dans notre classificateur :

Tableau 2.
Bien qu'il y ait eu un certain chevauchement dans la terminologie spécifique, il y avait des différences intéressantes dans l'interprétation de ce que ces noms signifiaient. Il y avait trois noms pour les environnements d'écoute utilisés par les auditeurs et le classificateur : "silence", "bruit" et "musique". Cependant, l'interprétation de chaque terme était souvent assez spécifique. « Silencieux » était utilisé très rarement par nos auditeurs et dépassait rarement 3 % pour tout environnement d'écoute. Par exemple, le fichier sonore du ventilateur en haut du tableau 1 a été attribué une probabilité de 100 % de « silencieux » par notre classificateur puisque le niveau global était de seulement 40 dB SPL, mais nos auditeurs l'ont qualifié de « bruit » 92 % du temps. Fait intéressant, nos auditeurs ne nous ont donné qu'une probabilité de "bruit" supérieure à 27 % dans seulement deux autres environnements d'écoute, tous deux assez bruyants. Les fichiers sonores vraiment bruyants contenaient tous de la parole et ont donc reçu les plus hautes probabilités de « parole dans le bruit » par nos auditeurs. Il en était de même pour le classificateur, sauf qu'il faisait une distinction sur la base du type de bruit, soit plusieurs interlocuteurs de fond ou du bruit de moteur tel que des trains, des voitures ou de la circulation. Ni les auditeurs ni le classificateur n'ont détecté « musique » très souvent, et seulement lorsqu'elle était beaucoup plus forte que tout le reste autour d'elle. Mais les auditeurs ont offert une catégorie distincte de « discours dans la musique » mélangée avec « discours dans le bruit » dans sept environnements où le classificateur a détecté un « grand groupe » (ce qu'ils étaient, mais le classificateur a ignoré la musique en faveur de l'optimisation du discours).
Les principales distinctions entre les auditeurs et le classificateur n'étaient pas tant qu'ils détectaient des choses différentes, mais qu'ils priorisaient différents aspects des fichiers sonores ou faisaient des distinctions légèrement plus précises dans certains cas. Par exemple, on pourrait facilement soutenir qu'un ventilateur doux à 40 dB SPL est à la fois silencieux et un bruit. Les deux sont des interprétations correctes du même environnement d'écoute.
La comparaison multiproduit :
Les résultats suivants montrent comment les produits premium de cinq fabricants, y compris Unitron, classifient plusieurs environnements d'écoute par rapport à nos jeunes auditeurs à l'audition normale. Cet exercice ne concerne pas qui a raison ou qui a tort – plutôt, c'est une occasion de voir comment différents classificateurs se comparent. Les résultats ont montré que certains instruments auditifs sont meilleurs en classification que d'autres, et les différentes philosophies des entreprises tendent à se révéler.
Recommençons avec un exemple simple. La figure 5 montre comment les jeunes auditeurs normaux et les cinq appareils auditifs ont classé un seul interlocuteur masculin venant de l'avant à 55 dB SPL.

Figure 5
Différents fabricants ont différents systèmes de classification qui utilisent différents noms pour les environnements d'écoute qu'ils classifient. En utilisant leurs descriptions de ce à quoi chaque destination d'écoute était destinée, nous avons regroupé les titres en quatre catégories principales : calme, discours dans le bruit, bruit et musique (comme indiqué dans la légende de la figure 5). Ces quatre catégories générales apparaissent dans tous les appareils auditifs que nous avons testés sous un nom ou un autre, mais nous avons utilisé les noms génériques dans nos résultats pour maintenir l'anonymat des fabricants et des appareils auditifs impliqués. Nos auditeurs normaux ont classé ce fichier sonore comme une écoute tranquille environ 98% du temps. Tous les cinq appareils auditifs ont fait la même chose.
La figure 6 est un peu plus complexe que la figure 5. Il y a encore une fois un seul interlocuteur directement devant l'auditeur, mais le niveau global du fichier sonore est maintenant de 80 dB SPL avec un SNR nominal de 0 dB. Le bruit de fond est un train de métro dans le métro de Londres, et les niveaux variaient à mesure que les trains arrivaient et partaient.

Figure 6
Nos auditeurs normaux ont classé ce fichier comme un discours dans le bruit environ 83% du temps. Ils ont également dit que c'était du bruit 4% du temps et calme 10% du temps. En tenant compte des différences de niveau à mesure que les trains arrivaient et partaient, il est juste de dire que Unitron et le concurrent D étaient les plus proches de ce que les jeunes auditeurs à l'audition normale nous ont dit. Le concurrent A n'était pas loin derrière, cependant, les concurrents B & C étaient très différents.
C'est là que les différences de philosophie sont d'abord exposées. Si nous regardons le concurrent B, cet instrument a classé l'environnement comme juste du bruit environ 50% du temps. Il est clair que nos auditeurs normaux rapportent la parole dans le bruit de manière assez cohérente. Par conséquent, le SNR doit être raisonnable la plupart du temps. Cependant, à 80 dB, le niveau global est assez élevé. Ainsi, nous en déduisons que le concurrent B a une philosophie qui est plus sensible au niveau global qu'au SNR dans ce cas, comme les quatre autres appareils auditifs testés.
L'arrière-plan devient encore plus complexe dans la figure 7. Ici, les auditeurs évaluaient un seul interlocuteur de face dans un arrière-plan d'une aire de restauration au centre commercial près de l'heure du déjeuner. Le niveau global était un peu plus bas à 70 dB SPL à un SNR de 0 dB. C'est un arrière-plan complexe de dizaines de personnes menant de nombreuses conversations à la fois ainsi que le bruit des cuisines servant de la nourriture et des gens passant.

Figure 7
Dans ce cas, nos auditeurs à l'audition normale rapportent environ 47 % de discours dans le bruit et environ 50 % de bruit seulement. Les autres 3% étaient de la musique. Cette fois-ci, les résultats du classificateur varient considérablement selon les fabricants. Bien que tous les classificateurs aient offert une certaine combinaison de parole dans le bruit et de bruit, les pourcentages pour les concurrents A & C étaient complètement opposés à ceux des concurrents B & D.
Ceci pourrait être l'exemple parfait des différences philosophiques dans ce que le scientifique de l'audition de Unitron, Leonard Cornelisse, appelle "le point d'abandon". Il définit le point d'abandon comme le niveau de signal et/ou le SNR où le porteur de l'appareil auditif "abandonne" en essayant de suivre le discours parce que la situation est devenue trop difficile. En dessous du point d'abandon, l'auditeur travaillera à suivre ce qui est dit et le rapportera comme un discours dans un environnement bruyant, en s'attendant à ce que l'appareil auditif mette l'accent sur la clarté de la parole. Mais une fois le point de renoncement franchi, l'auditeur rapporte qu'il est trop difficile de suivre le discours ou trop fort pour écouter confortablement, et il aimerait que l'appareil auditif privilégie le confort plutôt que la clarté. Chaque classificateur est conçu pour prendre cette décision à un moment donné, et c'est une décision purement acoustique. (À moins que l'auditeur ne passe à un programme manuel pour le remplacer.)
La première conclusion de la Figure 7 est que les concurrents A & C supposent un point d'abandon plus élevé que les concurrents B & D. Tant Unitron que les auditeurs normaux ont indiqué que cet environnement est assez bien situé sur la ligne du point d'abandon avec une répartition presque 50/50 entre la parole dans le bruit et le bruit. C'est peut-être l'exemple le plus frappant de la philosophie influençant la performance. Étant donné que le point d'abandon pour différentes personnes malentendantes varie souvent considérablement, qui peut dire laquelle de ces entreprises réussira parfaitement pour un auditeur particulier ?
Le dernier exemple est pour écouter de la musique. Dans la figure 8, nous voyons les résultats pour la musique jouée seule (sans autres sons de fond) à un niveau de 65 dB SPL. Ce n'est pas un niveau élevé pour écouter de la musique et ne reproduit pas une performance en direct. Plutôt, c'est plus proche du niveau auquel un porteur d'appareil auditif peut écouter de la musique tout en cuisinant ou en lisant un livre, mais un peu plus fort que la musique de fond.

Figure 8
Dans ce cas, les auditeurs normaux, Unitron, Compétiteur A et Compétiteur C ont tous indiqué qu'il s'agissait essentiellement d'un environnement d'écoute de musique pure. Les concurrents B & D l'ont classé différemment au moins 33 % et 20 % du temps, respectivement. La classification erronée la plus courante dans ce cas était pour le discours dans le bruit, et c'est le seul cas où une erreur claire et indéfendable s'est produite. Confondre la musique avec la parole dans le bruit équivaut à configurer un appareil auditif pour exactement le type de performance opposé que vous préféreriez. Il est généralement admis de créer un environnement musical pour une reproduction à large bande légèrement traitée. Mais la parole dans le bruit reçoit généralement une forte dose de microphones directionnels et d'annulation de bruit conçus, entre autres, pour réduire l'amplification des basses fréquences. Pour être juste, un tel échec n'était pas courant pour les cinq classificateurs.
Résumé
La classification des scènes sonores des instruments auditifs est un sujet qui reçoit très peu d'attention. Pourtant, c'est l'un des composants les plus importants de l'architecture de l'instrument. Fonctionnant discrètement en arrière-plan, les classificateurs prennent toutes les décisions concernant les ensembles de paramètres de traitement les plus valides dans un environnement d'écoute donné, et influencent fortement la façon dont un porteur entend.
Les décisions de classification sont basées autant sur la philosophie que sur l'acoustique. Ainsi, tous les classificateurs ne sont pas égaux dans toutes les situations. La plupart du temps, particulièrement dans des situations d'écoute simples, presque tous les meilleurs appareils auditifs convergeront vers des résultats très cohérents qui correspondent à la façon dont un auditeur avec une audition normale classifierait l'environnement. Mais une fois que l'environnement d'écoute devient plus complexe, les différences de philosophie et parfois de performance deviennent évidentes.
Avec SoundNav, un classificateur entraîné à l'aide de l'intelligence artificielle, les résultats de Unitron sont très cohérents avec ceux de nos jeunes auditeurs normaux.
Remerciements :
Je tiens à remercier la participation du Dr Ozmeral et du Dr Eddins qui ont collaboré étroitement avec nous au développement du « parkour » sonore et à la collecte de données dans leur laboratoire de l’Université de Floride du Sud.
Références :
Büchler, M., Allegro, S., Launer, S., & Dillier, S. (2005). Classification sonore dans les aides auditives inspirée par l'analyse de la scène auditive.EURASIP Journal on Applied Signal Processing, 18, 2991–3002.
Kates, J. M. (1995). Classification des bruits de fond pour les applications d'appareils auditifs.J Acoust Soc Am, 97(1), 461-470.
Lamarche, L., Giguere, C., Gueaieb, W., Aboulnasr, T., & Othman, H. (2010). Système de classification adaptative de l'environnement pour les appareils auditifs.J Acoust Soc Am, 127(5), 3124-3135. doi:10.1121/1.3365301
Nordqvist, P., & Leijon, A. (2004). Un algorithme de classification sonore efficace et robuste pour les appareils auditifs.J Acoust Soc Am, 115(6), 3033-3041.
Autres articles pouvant vous intéresser
