Was ist das große Problem mit Hörgeräteklassifizierern?
Einführung
Moderne Hörgeräte bieten alle einen gewissen Grad an automatischer Programmumschaltung basierend auf akustischer Klassifizierung. Die einfachsten dieser Geräte sind fast seit der Jahrhundertwende erhältlich – und es ist schwer zu glauben, dass seitdem 19 Jahre vergangen sind! Haben Sie jemals darüber nachgedacht, wie das Klassifizierungssystem leise die Leistung von Hörgeräten beeinflusst?
Während es noch einige Personen gibt, die ihre Hörgeräte manuell steuern möchten, ziehen es die meisten Menschen vor, sie aufzusetzen und zu vergessen, sodass die Hörgeräte sich automatisch an ihre sich ändernden Hörumgebungen anpassen. Das legt viel Verantwortung auf die Genauigkeit der Klassifizierung, zu der dieses Gerät fähig ist.
Da digitale Hörgeräte immer ausgefeilter geworden sind, hat sich ihre Leistung stetig verbessert. Aber auch die Komplexität der zugrunde liegenden akustischen Klassifizierungsschemata, die dies alles möglich machen. Mit der Einführung von Indigo im Jahr 2005 führte Unitron ein neues Klassifizierungssystem ein. Es war unser erster Klassifikator, der mit künstlicher Intelligenz trainiert wurde, um zwischen vier verschiedenen akustischen Szenen zu unterscheiden: ruhiges Zuhören, Sprache im Lärm, Lärm und Musik.
Mit der Einführung unseres Konversationsklassifikators auf der North-Plattform wurden wir so zuversichtlich in unsere Fähigkeit, sieben verschiedene Hörumgebungen korrekt zu klassifizieren, dass wir die Klassifikatorausgabe verwenden, um Log It All zu steuern, ein Branchenneuheit von Unitron. Während die Datenprotokollierung Ihnen zeigt, was das Hörgerät im Laufe der Zeit tut, zeigt Ihnen Log It All, wie viel Zeit der Träger in jedem der sieben Hörumgebungen verbringt – und gibt Ihnen einen Überblick über den Hörlebensstil des Trägers, um Ihnen zu helfen, die Erfahrung des Trägers in jeder Umgebung zu individualisieren. Damit Log It All jedoch von Wert ist, müssen wir sicher sein, dass der Klassifikator diese Hörumgebungen genau kategorisiert.
Die Klassifizierung ist noch wichtiger für eine gute Benutzererfahrung. Sie können die Parameter für jede Hörumgebung beim ersten Anpassen perfekt einstellen, aber wenn der Klassifikator, der das automatische Programmumschalten steuert, die akustische Umgebung falsch erkennt, wird das alles keine Rolle spielen. Wenn der Klassifikator beispielsweise denkt, dass der Träger Musik hört, während er tatsächlich in einer ruhigen Umgebung ein Gespräch führt, wird die Leistung des Hörgeräts unterdurchschnittlich sein, da es für die falsche Hörumgebung optimiert ist.
Folglich ist die präzise Klassifizierung ein absolut kritischer Bestandteil des Erfolgs mit modernen Hörgeräten. Bei Unitron wollten wir wissen: Machen wir es richtig? Haben wir unseren Klassifikator darauf trainiert, die tatsächlichen akustischen Umgebungen, in denen Verbraucher ihre Zeit verbringen, genau zu erkennen?
Um unsere Fragen zu beantworten, haben wir eine Benchmark-Studie unseres Konversationsklassifikators an der University of South Florida mit Dr. David Eddins und Dr. Erol Ozmeral durchgeführt.
Was Klassifikatoren tun:
Automatische Klassifikatoren erfassen die aktuelle akustische Umgebung und erzeugen Wahrscheinlichkeiten für jeden der im automatischen Programm verfügbaren Hörziele. Das Hörgerät wechselt zu dem Hörprogramm, für das die höchste Wahrscheinlichkeit erzeugt wird. Es wird erneut wechseln, wenn sich die akustische Umgebung ausreichend ändert, sodass eine andere Hörumgebung eine höhere Wahrscheinlichkeit erzeugt.
Allerdings funktionieren nicht alle Klassifizierungsschemata auf die gleiche Weise. Was sie einzigartig macht, ist die Philosophie der Ingenieure, die sie erschaffen. Es sind diese Philosophien, die ihre Entscheidungen darüber beeinflussen, welche Aspekte einer bestimmten akustischen Umgebung sie von allen anderen unterscheiden. Betrachten Sie dies: Zwei Hersteller von Hörgeräten könnten derselben akustischen Umgebung ausgesetzt sein und sie unterschiedlich klassifizieren. Warum passiert das? Es liegt daran, dass die Designer der beiden Systeme den verschiedenen Aspekten dieser akustischen Umgebung unterschiedliche Gewichtungen zugewiesen haben. Daher haben die Geräte verschiedene Aspekte der Umgebung gemessen und unterschiedliche Entscheidungen über die Werte dessen getroffen, was sie erkannt haben. So können sie unterschiedliche Schlussfolgerungen über die akustische Umgebung selbst ziehen.
Betrachten Sie beispielsweise diese repräsentativen Ansätze zur akustischen Klassifizierung in Hörgeräten:
- (Kates, 1995) beschrieb ein System, das auf der Clusteranalyse von Hüllkurvenmodulation und Spektralmerkmalen basiert, um Hintergrundgeräusche in elf Klassen zu klassifizieren: Wohnung, Stimmengewirr, Abendessen, Geschirr, Gauß, Drucker, Verkehr, Tippen, männlicher Sprecher, Sirene und Belüftung.
- (Nordqvist & Leijon, 2004) verwendeten versteckte Markov-Modelle, um ein robustes Klassifizierungssystem für Hörgeräte zu entwickeln, das drei Klassen enthält: Sprache im Verkehrslärm, Sprache im Stimmengewirr und saubere Sprache.
- (Büchler, Allegro, Launer, & Dillier, 2005) klassifizierten saubere Sprache, Sprache im Lärm, Lärm und Musik mit mehreren Ansätzen. Die Autoren erklärten viele Arten der Merkmalsextraktion und verglichen dann sechs verschiedene Klassifikatoren mit niedriger bis mittlerer Komplexität, die für den HA-Einsatz erforderlich sind.
- (Lamarche, Giguere, Gueaieb, Aboulnasr, & Othman, 2010) testeten zwei Systeme: Mindestabstand und Bayes-Klassifikatoren. In jedem Fall kann sich der Klassifikator an die einzigartigen Umgebungen der Zuhörer anpassen und sich entsprechend abstimmen. Sie wählten charakteristische Merkmale, die gut geeignet sind, um zwischen Sprach-, Geräusch- und Musikumgebungen zu unterscheiden, einschließlich Tiefe der Amplitudenmodulationen, Modulationsfrequenzbereiche (0 – 4 Hz & 4 – 16 Hz) und zeitliche Varianz der momentanen Frequenz. Sie stellten fest, dass beide Methoden gut funktionierten. Aber sie neigten dazu, Klassen anders zusammenzuführen, wenn sie von drei auf zwei Klassen zusammenführten.
Auch wenn diese Liste nicht erschöpfend ist, zeigt sie viele der Ansätze, die Ingenieuren und Wissenschaftlern zur Verfügung stehen, die diese Algorithmen entwickeln. Während die Philosophien der Hörgeräteunternehmen proprietär sind, ist es dennoch möglich, diese Schemata miteinander und mit einem Goldstandard zu vergleichen, um zu bewerten, was verschiedene Systeme zu bieten haben. Zu diesem Zweck haben wir einen Benchmark-Ansatz entwickelt, der auf der Replikation realer Hörumgebungen in einer kontrollierten und wiederholbaren Umgebung basiert. Der Ansatz und einige der Ergebnisse werden in diesem Papier beschrieben.
Der Benchmarking-Ansatz:
Wir haben uns entschieden, die Klassifikatoren zu bewerten, indem wir zwei Arten von Vergleichen anwenden. Zuerst haben wir alle Hörgeräteklassifikatoren mit einem menschlichen Goldstandard verglichen. Zweitens haben wir die Klassifizierergebnisse für Hörgeräte von fünf Herstellern miteinander verglichen. Beide Ansätze bieten nützliche Einblicke.
Der Standort
Wir haben alle Messungen im Auditory & Speech Sciences Laboratory an der University of South Florida durchgeführt. Der Klangraum ist in Abbildung 1 dargestellt.

Abbildung 1
Der Stuhl in der Mitte des Raumes ist von einer Anordnung von 64 unabhängig betriebenen Lautsprechern auf Ohrhöhe umgeben. Obwohl der Raum eine traditionell schallbehandelte Testkammer ist, können Plexiglasplatten an den Wänden und der Decke montiert werden, um eine natürlicher hallende Umgebung zu schaffen. Menschliche Teilnehmer sitzen auf dem Stuhl in der Mitte des Raumes, während sie Hörumgebungen bewerten. Wir erhielten Hörgerätedaten in Sätzen von jeweils drei Geräten mit einem Klangfinder anthropomorphischen System (Abbildung 2).
Indem die menschlichen Teilnehmer im Zentrum des Raumes durch den Klangfinder ersetzt wurden, war es möglich, alle Testbedingungen für alle Probanden und alle Hörgeräte an einem Ort zu wiederholen.

Abbildung 2
Der Sound Parkour
Wir begannen die Messübung, indem wir einen Klang-Parkour erstellten – eine Art akustischer Hindernisparcours, um die Klassifikatoren auf die Probe zu stellen. Wir definierten den Parkour in mehreren Dimensionen, wie im Kopfbereich und der linken Spalte von Tabelle 1 gezeigt. Jede Zeile von Tabelle 1 beschreibt die Zusammensetzung einer einzelnen Audiodatei, die zwei Minuten dauert und eine spezifische Hörumgebung darstellt. Diese Iteration des Parkours enthält 26 Hörumgebungen (Sounddateien). Die einfachste Hörumgebung wird als ruhiges Hören bezeichnet (in der obersten Reihe). Es gibt keine Sprache, nur das sanfte Geräusch eines Ventilators, der gleichmäßig mit einem Gesamtpegel von 40 dB SPL läuft. Es gibt fast keine Modulation und keine zeitlichen oder spektralen Kontraste – nur ein sanftes, gleichmäßiges Rauschen.
Wenn Sie die Tabelle hinuntergehen, werden die Hörumgebungen komplexer. Zum Beispiel sehen Sie in der linken Spalte, dass wir mehr Sprecher und verschiedene Arten von Hintergrundgeräuschen hinzugefügt haben. Wir haben auch mit verschiedenen Musik- und Hintergrundgeräuschpegeln in Kombination mit Sprache in den sehr komplexen Umgebungen experimentiert.
Es gibt auch eine Richtungskomponente in den Sprach-, Geräusch- und Musikelementen. Wenn weitere Lautsprecher hinzugefügt werden, wird ihre Ausrichtung relativ zur Vorderseite der Hörgeräte aktualisiert, um widerzuspiegeln, wo ein Lautsprecher normalerweise in dieser Umgebung stehen oder sitzen würde. Dieser Schritt berücksichtigt alle Auswirkungen der Richtungsverarbeitung. Beispielsweise beachten Sie die Ausrichtung der Lautsprecher – links, rechts und vorne – in der U-Bahn-Umgebung. Diese „Sprecherverteilung“ ist das, was Sie auf einem U-Bahnsteig in der Londoner U-Bahn erleben würden, wenn Sie zwischen zwei Begleitern sitzen und eine andere Person vor Ihnen ein Gespräch führt. Die Richtkomponente wird auch für das Rauschen und die Musik in den Sounddateien verwendet. Mehrere Iterationen des Sound-Parkours wurden verwendet, von denen Tabelle 1 (download Tabelle 1) ein repräsentatives Beispiel ist.
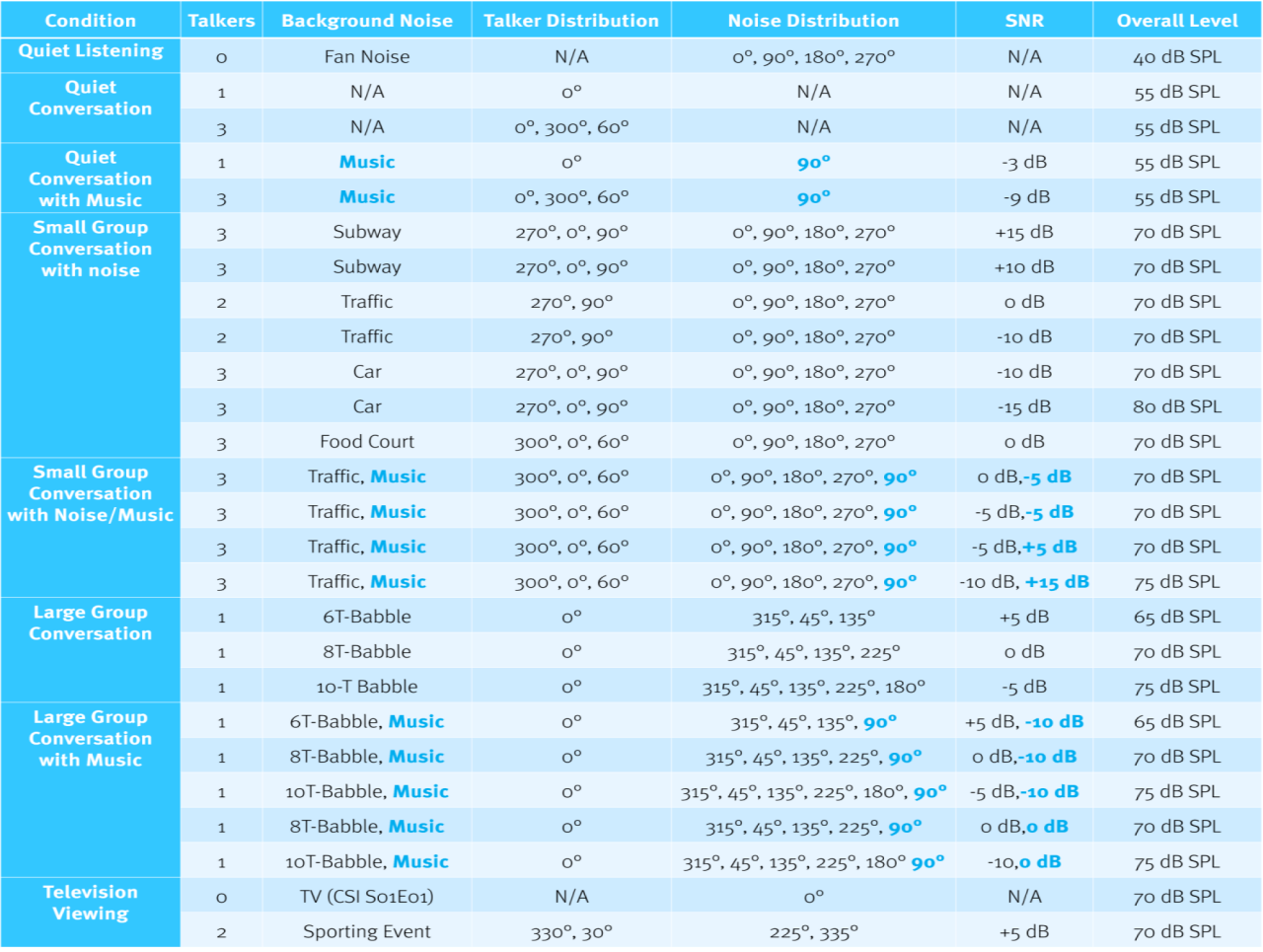
Tabelle 1.
Jede Audiodatei wurde acht Stunden lang kontinuierlich für jede Gruppe von Hörgeräten im Klangfinder wiederholt. Es gab keinen direkten Weg, die Klassifikator-Wahrscheinlichkeiten von den meisten Geräten abzulesen. Stattdessen haben wir uns auf die Datenprotokollierungsergebnisse für acht Stunden einer einzigen Datei verlassen, um festzustellen, wie der Klassifikator jedes Herstellers diese spezielle Hörumgebung protokolliert hat. Da die Datenprotokollierung der in einer bestimmten Hörumgebung verbrachten Zeit höchstwahrscheinlich durch Klassifikator-Wahrscheinlichkeiten über die Zeit gesteuert wird, war das Schleifen einer einzigen Audiodatei für acht Stunden/Sitzung die logischste Methode, um stabile Klassifikator-Ergebnisse zu erzielen.
Wie sehen die tatsächlichen Klassifizierergebnisse aus?
Bevor wir uns die Ergebnisse ansehen, die indirekt von den Hörgeräten fünf verschiedener Hersteller mithilfe der Datalogging-Ausgabe gewonnen wurden, ist es aufschlussreich, detailliertere Ergebnisse von Unitron-Hörgeräten zu betrachten. Es ist möglich für Drs. Eddins und Ozmeral sollen die Klassifikatorwahrscheinlichkeiten von unserem Hörgerät sofort mehrmals pro Sekunde auslesen, während sie erzeugt werden. Abbildungen 3 und 4 zeigen die tatsächlichen Klassifikatorwahrscheinlichkeiten, wie sie von einem Paar Unitron-Hörgeräten mit diesem Ansatz bestimmt wurden. Der erste Fall, Abbildung 3, zeigt 60 Sekunden lang Klassifikatorwahrscheinlichkeiten für zwei sehr einfache Hörumgebungen.

Abbildung 3
Am oberen Rand von Abbildung 3 sehen wir 60 Sekunden der ursprünglichen Wiedergabe. Die erste Hälfte dieser Abbildung zeigt die letzten 30 Sekunden der WAV-Dateiaufnahme der sanften Lüfterumgebung (die oberste Zeile von Tabelle 1). Die zweite Hälfte zeigt die ersten 30 Sekunden der zweiminütigen Aufnahme der leisen Gesprächs-WAV-Datei mit einem einzelnen Sprecher (zweite Zeile von Tabelle 1). Diese einfachen Hörumgebungen zeigen, wie der Klassifikator Wahrscheinlichkeiten erzeugt, die fast ausschließlich eine einzige akustische Hörumgebung repräsentieren.
Das untere Zentrum der Abbildung ist zeitlich mit den Aufnahmen synchronisiert und zeigt die Verteilung der Wahrscheinlichkeiten für jede der sieben möglichen Hörumgebungen im Unitron-Klassifikator. Die ersten 30 Sekunden besteht eine 100%ige Wahrscheinlichkeit, dass dies eine ruhige Hörumgebung ist. Angesichts der Tatsache, dass es sich um eine Aufnahme eines leisen Ventilators handelt, der in einem schallbehandelten Raum mit nur 40 dB SPL gemessen wurde, ist diese Klassifizierung korrekt. Das Hörgerät würde diese 30 Sekunden in der ruhigen Hörumgebung von SoundNav verbringen.
Nach 30 Sekunden wechselt die Aufnahme abrupt vom leisen Ventilator bei 40 dB SPL zu einem einzelnen Sprecher bei 55 dB SPL. Von 30 Sekunden bis ungefähr 37 Sekunden sind die Klassifikator-Wahrscheinlichkeiten im Übergang. Beachten Sie, wie die Wahrscheinlichkeit des Sprechens in Ruhe sofort zu steigen beginnt, während die Wahrscheinlichkeit des ruhigen Zuhörens sinkt. Die beiden Wahrscheinlichkeiten schneiden sich bei ungefähr 35 Sekunden. In dieser Übergangszone wechselt SoundNav das Hörgerät von der ruhigen Hörumgebung zur Sprach-in-ruhiger-Hörumgebung. Der Klassifikator erkennt die Änderung tatsächlich fast sofort, aber unsere Entwickler haben bewusst entschieden, dass das Gerät nicht zu schnell auf jede kleine Änderung in der akustischen Umgebung reagieren soll. Schnelle Veränderungen könnten zu einer verminderten Klangqualität in dynamischen Hörumgebungen führen, da SoundNav versucht, mit allen Umweltveränderungen Schritt zu halten.
Nach 40 Sekunden und für die letzten 20 Sekunden der Aufnahme liegt die Wahrscheinlichkeit einer Rede in einer ruhigen Hörumgebung bei fast 100%.
Die beiden vertikalen Balken links und rechts im Abschnitt der Klassifizierungsproportionen zeigen den Anteil der Zeit, die in jedem der sieben möglichen Hörumgebungen für das Paar von zwei Minuten langen WAV-Dateien verbracht wird. Der rote Balken links zeigt die vollen zwei Minuten der sanften Lüfter-WAV-Datei, und der rote und blaue Balken rechts zeigen den Anteil der Zeit, die in jedem der sieben Hörumgebungen während der zwei Minuten der Sprachaufnahme in der ruhigen WAV-Datei verbracht wurde. Der leicht rote Abschnitt stellt die Übergangszeit zu Beginn der Rede in der ruhigen Aufnahme dar.
Abbildung 4 ist ein Beispiel dafür, was in einer komplexeren Hörumgebung passiert.

Abbildung 4
Hier können wir den Einfluss auf die Wahrscheinlichkeiten von zwei viel komplexeren Hörumgebungen sehen. In beiden Fällen fährt der Zuhörer im Auto zusammen mit drei Sprechern. Auf der linken Seite (die ersten 30 Sekunden) ist das Auto viel leiser mit einem Gesamtpegel von etwa 70 dB und einem -10 dB SNR. Die allgemeinen Pegel sind in den zweiten 30 Sekunden bei einem Gesamtsignalpegel von 80 dB mit -15 dB SNR viel schwieriger. Diese Pegel mögen für einen Hörgeräteträger wie nahezu unmögliche SNRs erscheinen, aber das Autogeräusch ist insofern charakteristisch, als fast die gesamte Energie in den sehr niedrigen Frequenzen liegt (unter 1000 Hz). Als solche sehen die SNRs extrem aus, aber fast alle hochfrequenten Sprachanteile sind in beiden WAV-Dateien deutlich hörbar.
Während das Auto die Geschwindigkeit ändert und die Sprecher beginnen und aufhören, variieren die Klassifikator-Wahrscheinlichkeiten stark über eine Mischung aus drei verschiedenen Hörumgebungen. Während der weicheren ersten 30 Sekunden besteht die höchste Wahrscheinlichkeit für ein Gespräch in einer kleinen Gruppe, durchschnittlich 50 % bis 60 %. Wie Sie vielleicht erwarten, wird auch das Gespräch im Lärm erkannt, wobei es von 0% bis 50% variiert. Gespräche in einer großen Gruppe haben eine kleinere, aber dennoch bemerkbare Wahrscheinlichkeit, die sich durchgehend um 15 % bis 20 % bewegt. Sobald das Gesamtniveau steigt und das SNR schlechter wird, wird das Geräusch des Autolärms vorherrschend. Wenn das Auto beschleunigt, verschieben sich die Klassifikator-Wahrscheinlichkeiten stark in die Umgebung von Gesprächen im Lärm, und Gespräche in einer kleinen Gruppe fallen unter 20%.
Nehmen Sie sich einen Moment Zeit, um über diese beiden Beispiele nachzudenken. Der erste ist einfach. Nach dem Benchmarking von Hörgeräten vieler Hersteller ist klar, dass jedes einzelne in beiden Hörumgebungen, die in Abbildung 3 gezeigt sind, ähnlich reagieren würde.
Aber was ist mit den beiden Umgebungen in Abbildung 4? Hier spielt die Philosophie eine Rolle. In diesen Hörumgebungen passiert viel und Entwickler müssen einige Entscheidungen darüber treffen, was zu tun ist. Zum Beispiel, was ist wichtiger: das Autogeräusch zu eliminieren oder die Sprache zu verbessern? Ab welchem Punkt ist das Gesamtniveau zu laut und es lohnt sich nicht, sich um die Sprache zu kümmern? Ist diese Entscheidung auf dem Gesamtniveau oder dem SNR basiert? Der Sound-Parkour ist darauf ausgelegt, all diese Möglichkeiten zu betrachten, um herauszufinden, welche relevanten Entscheidungen getroffen wurden.
Der Goldstandard:
Tabelle 1 listet Audiodateien auf, die mehrere allgemeine Hörumgebungen darstellen, denen ein Hörgeräteträger im wirklichen Leben begegnen könnte. Wie wussten wir, dass die Dateien die vorgesehenen Hörumgebungen genau repräsentierten? Wir hatten 17 normal hörende Zuhörer, die für uns definierten, welche Hörumgebungen ihrer Meinung nach am besten durch jede Audiodatei repräsentiert wurden. (Mehrere Antworten waren akzeptabel.) Die Sounddateien wurden unseren Zuhörern in zufälliger Reihenfolge abgespielt. Sie hörten jede Audiodatei dreimal und beschrieben die Umgebung für jede Iteration jeder Audiodatei. Wir haben dann alle ihre Antworten zusammengefasst, um sie mit den Hörgeräteklassifikatoren zu vergleichen.
In Tabelle 2 sehen wir, wie die Beschreibungen unserer menschlichen Zuhörer im Vergleich zu den sieben Hörumgebungen in unserem Klassifikator abschneiden:

Tabelle 2.
Obwohl es einige Überschneidungen in der spezifischen Terminologie gab, gab es interessante Unterschiede in der Interpretation dessen, was diese Namen bedeuteten. Es gab drei Namen für Hörumgebungen, die sowohl von den Zuhörern als auch vom Klassifikator verwendet wurden: "ruhig", "Lärm" und "Musik". Die Interpretation jedes Begriffs war jedoch oft sehr spezifisch. „Leise“ wurde von unseren Zuhörern sehr selten verwendet und überschritt selten 3 % für jede Hörumgebung. Zum Beispiel wurde die Lüftergeräuschdatei oben in Tabelle 1 von unserem Klassifikator mit einer Wahrscheinlichkeit von 100 % als „leise“ eingestuft, da der Gesamtpegel nur 40 dB SPL betrug, aber unsere Zuhörer nannten es 92 % der Zeit „Lärm“. Interessanterweise gaben uns unsere Zuhörer nur in zwei anderen Hörumgebungen eine Wahrscheinlichkeit von "Geräusch" über 27%, die beide ziemlich laut waren. Die wirklich lauten Tondateien enthielten alle Sprache und wurden daher von unseren Zuhörern mit den höchsten Wahrscheinlichkeiten für "Sprache im Lärm" bewertet. Das Gleiche galt für den Klassifikator, außer dass er eine Unterscheidung auf der Grundlage der Art des Geräusches machte, entweder mehrere Hintergrundsprecher oder Motorengeräusche wie Züge, Autos oder Verkehr. Weder die Zuhörer noch der Klassifikator erkannten "Musik" sehr oft, und nur wenn sie viel lauter war als alles andere um sie herum. Aber die Zuhörer boten eine eigene Kategorie von „Sprache in Musik“ gemischt mit „Sprache im Lärm“ in sieben Umgebungen an, in denen der Klassifikator eine „große Gruppe“ erkannte (was sie waren, aber der Klassifikator ignorierte die Musik zugunsten der Optimierung der Sprache).
Die Hauptunterschiede zwischen den Zuhörern und dem Klassifikator bestanden nicht so sehr darin, dass sie unterschiedliche Dinge erkannten, sondern darin, dass sie unterschiedliche Aspekte der Audiodateien priorisierten oder in einigen Fällen etwas präzisere Unterscheidungen trafen. Zum Beispiel könnte man leicht argumentieren, dass ein leiser Ventilator bei 40 dB SPL sowohl leise als auch ein Geräusch ist. Beide sind korrekte Interpretationen derselben Hörumgebung.
Der Mehrproduktvergleich:
Die folgenden Ergebnisse zeigen, wie Premiumprodukte von fünf Herstellern, einschließlich Unitron, verschiedene Hörumgebungen im Vergleich zu unseren jungen normal hörenden Zuhörern klassifizieren. Diese Übung geht nicht darum, wer Recht hat oder wer Unrecht hat – vielmehr ist es eine Gelegenheit, zu sehen, wie verschiedene Klassifikatoren im Vergleich abschneiden. Die Ergebnisse zeigten, dass einige Hörgeräte besser in der Klassifizierung sind als andere, und die unterschiedlichen Philosophien der Unternehmen neigen dazu, sich zu offenbaren.
Lassen Sie uns mit einem einfachen Beispiel erneut beginnen. Abbildung 5 zeigt, wie die jungen normalen Zuhörer und die fünf Hörgeräte einen einzelnen männlichen Sprecher von vorne bei 55 dB SPL klassifizierten.

Abbildung 5
Verschiedene Hersteller haben unterschiedliche Klassifizierungsschemata, die unterschiedliche Namen für die Hörumgebungen verwenden, die sie klassifizieren. Anhand ihrer Beschreibungen, wofür jeder Hörzielort gedacht war, haben wir die Titel in vier Hauptkategorien gruppiert: Ruhe, Sprache im Lärm, Lärm und Musik (wie in der Legende von Abbildung 5 gezeigt). Diese vier allgemeinen Kategorien erscheinen in allen Hörgeräten, die wir unter einem oder anderem Namen getestet haben, aber wir haben in unseren Ergebnissen die generischen Namen verwendet, um die Anonymität der beteiligten Hersteller und Hörgeräte zu wahren. Unsere normalen Zuhörer klassifizierten diese Tondatei etwa 98% der Zeit als ruhiges Zuhören. Alle fünf Hörgeräte machten dasselbe.
Abbildung 6 ist etwas komplexer als Abbildung 5. Es gibt wieder einen einzelnen Sprecher direkt vor dem Zuhörer, aber der Gesamtpegel der Audiodatei beträgt jetzt 80 dB SPL mit einem nominalen SNR von 0 dB. Das Hintergrundgeräusch ist ein U-Bahn-Zug in der Londoner U-Bahn, und die Pegel variierten, als Züge ankamen und abfuhren.

Abbildung 6
Unsere normalen Zuhörer klassifizierten diese Datei etwa 83% der Zeit als Sprache im Lärm. Sie sagten auch, dass es 4% der Zeit Lärm und 10% der Zeit ruhig war. Wenn man die Niveauunterschiede berücksichtigt, während Züge kamen und gingen, kann man fairerweise sagen, dass Unitron und Konkurrent D am nächsten an dem waren, was uns die jungen normal hörenden Zuhörer mitgeteilt haben. Konkurrent A war nicht weit zurück, jedoch waren Konkurrenten B & C sehr unterschiedlich.
Hier werden die Unterschiede in der Philosophie erstmals offengelegt. Wenn wir uns Wettbewerber B ansehen, hat dieses Instrument die Umgebung etwa 50% der Zeit nur als Lärm klassifiziert. Es ist klar, dass unsere normalen Zuhörer Sprache im Lärm ziemlich konsistent melden. Daher muss das SNR die meiste Zeit vernünftig sein. Allerdings ist der Gesamtpegel bei 80 dB ziemlich hoch. Daher schließen wir, dass Konkurrent B in diesem Fall eine Philosophie hat, die empfindlicher auf das Gesamtniveau als auf das SNR reagiert, ähnlich wie die anderen vier getesteten Hörgeräte.
Der Hintergrund wird in Abbildung 7 noch komplexer. Hier bewerteten die Zuhörer einen einzelnen Sprecher von vorne in einem Hintergrund eines Food-Courts im Einkaufszentrum zur Mittagszeit. Das Gesamtniveau war etwas niedriger bei 70 dB SPL bei einem 0 dB SNR. Dies ist ein komplexer Hintergrund von Dutzenden von Menschen, die gleichzeitig viele Gespräche führen, sowie das Geräusch der Küchen, die Essen servieren, und Menschen, die vorbeigehen.

Abbildung 7
In diesem Fall berichten unsere normal hörenden Zuhörer über etwa 47% Sprache im Lärm und etwa 50% nur Lärm. Die anderen 3% waren Musik. Diesmal variieren die Klassifizierergebnisse stark zwischen den Herstellern. Während alle Klassifikatoren eine Kombination aus Sprache im Lärm und Lärm anboten, waren die Prozentsätze für Wettbewerber A & C genau das Gegenteil von denen für Wettbewerber B & D.
Dies könnte das perfekte Beispiel für philosophische Unterschiede in dem sein, was der Unitron-Hörwissenschaftler Leonard Cornelisse als „den Aufgabepunkt“ bezeichnet. Er definiert den Aufgabepunkt als das Signalniveau und/oder SNR, bei dem der Träger des Hörgeräts "aufgibt", dem Gespräch zu folgen, weil die Situation zu schwierig geworden ist. Unterhalb des Aufgabepunktes wird der Zuhörer versuchen, dem Gesagten zu folgen und es als eine Rede in einer Geräuschumgebung zu berichten, wobei erwartet wird, dass das Hörgerät die Sprachklarheit betont. Aber sobald der Punkt des Aufgebens überschritten ist, berichtet der Zuhörer, dass es zu schwierig ist, der Rede zu folgen oder zu laut, um bequem zuzuhören, und sie möchten, dass das Hörgerät Komfort über Klarheit betont. Jeder Klassifikator ist darauf ausgelegt, diese Entscheidung irgendwann zu treffen, und es ist eine rein akustisch getriebene Entscheidung. (Es sei denn, der Zuhörer wechselt zu einem manuellen Programm, um es zu überschreiben.)
Die erste Erkenntnis aus Abbildung 7 ist, dass die Konkurrenten A & C einen höheren Aufgabepunkt annehmen als die Konkurrenten B & D. Sowohl Unitron als auch die normalen Zuhörer haben angegeben, dass diese Umgebung ziemlich genau auf der Aufgabepunktlinie liegt, mit einer nahezu 50/50-Aufteilung zwischen Sprache im Lärm und Lärm. Dies ist vielleicht das auffälligste Beispiel dafür, wie Philosophie die Leistung beeinflusst. Angesichts der Tatsache, dass der Aufgabepunkt für verschiedene hörgeschädigte Menschen oft stark variiert, wer kann sagen, welches dieser Unternehmen es für einen bestimmten Zuhörer absolut richtig machen wird?
Das letzte Beispiel ist zum Musikhören. In Abbildung 8 sehen wir die Ergebnisse für Musik, die allein gespielt wird (ohne andere Hintergrundgeräusche) bei einem Pegel von 65 dB SPL. Dies ist kein hohes Niveau zum Musikhören und reproduziert keine Live-Performance. Vielmehr liegt es näher an dem Niveau, auf dem ein Hörgeräteträger Musik hören kann, während er kocht oder ein Buch liest, aber etwas lauter als Hintergrundmusik.

Abbildung 8
In diesem Fall gaben die normalen Zuhörer, Unitron, Konkurrent A und Konkurrent C alle an, dass dies im Wesentlichen eine reine Musikhörumgebung war. Wettbewerber B & D klassifizierten es unterschiedlich, mindestens 33% bzw. 20% der Zeit. Die häufigste Fehlklassifizierung bei diesem Fall war bei Sprache im Lärm, und dies ist der eine Fall, bei dem ein klarer und unentschuldbarer Fehler auftrat. Musik mit Sprache im Lärm zu verwechseln, kommt dem gleich, ein Hörgerät genau für die entgegengesetzte Art der Leistung einzurichten, die Sie bevorzugen würden. Es ist allgemein anerkannt, eine Musikumgebung für breitbandig leicht verarbeitete Wiedergabe einzurichten. Aber Sprache im Lärm erhält normalerweise eine starke Dosis von Richtmikrofonen und Geräuschunterdrückung, die unter anderem dazu entwickelt wurden, die Verstärkung niedriger Frequenzen zu reduzieren. Um fair zu sein, ein solcher Fehler war für die fünf Klassifikatoren nicht üblich.
Zusammenfassung
Die Klassifizierung von Klanglandschaften bei Hörgeräten ist ein Thema, dem nur sehr wenig Aufmerksamkeit geschenkt wird. Dennoch ist es eines der wichtigsten Bestandteile der Architektur des Instruments. Leise im Hintergrund laufend, treffen Klassifikatoren alle Entscheidungen darüber, welche Sätze von Verarbeitungsparametern in einer bestimmten Hörumgebung am gültigsten sind, und beeinflussen stark, wie ein Träger hört.
Klassifizierungsentscheidungen basieren ebenso sehr auf Philosophie wie auf Akustik. Daher sind nicht alle Klassifikatoren in allen Situationen gleich. Die meiste Zeit, insbesondere in einfachen Hörsituationen, werden fast alle der besten Hörgeräte zu hoch konsistenten Ergebnissen führen, die damit übereinstimmen, wie ein normal hörender Zuhörer die Umgebung klassifizieren würde. Aber sobald die Hörumgebung komplexer wird, werden die Unterschiede in der Philosophie und manchmal in der Leistung offensichtlich.
Mit SoundNav, einem mit künstlicher Intelligenz trainierten Klassifikator, sind die Ergebnisse von Unitron sehr konsistent mit denen unserer jungen normal hörenden Zuhörer.
Danksagung
Ich möchte hier auf den Beitrag von Dr. Ozmeral und Dr. Eddins hinweisen, die eng mit uns zusammengearbeitet haben, um den Sound Parkour zu entwickeln und die Datenerhebung in ihrem Labor an der University of South Florida durchzuführen.
Referenzen:
Büchler, M., Allegro, S., Launer, S., & Dillier, S. (2005). Klangklassifizierung in Hörgeräten inspiriert von der Analyse auditiver Szenen.EURASIP Journal on Applied Signal Processing, 18, 2991–3002.
Kates, J. M. (1995). Klassifizierung von Hintergrundgeräuschen für Hörgeräteanwendungen.J Acoust Soc Am, 97(1), 461-470.
Lamarche, L., Giguere, C., Gueaieb, W., Aboulnasr, T., & Othman, H. (2010). Adaptives Umgebungsklassifizierungssystem für Hörgeräte.J Acoust Soc Am, 127(5), 3124-3135. doi:10.1121/1.3365301
Nordqvist, P., & Leijon, A. (2004). Ein effizienter robuster Klangklassifikationsalgorithmus für Hörgeräte.J Acoust Soc Am, 115(6), 3033-3041.
Möglicherweise sind Sie auch daran interessiert
