Wat is het grote probleem met hoortoestelclassificaties?
Introductie
Moderne hoortoestellen bieden allemaal een zekere mate van automatische programma-omschakeling op basis van akoestische classificatie. De eenvoudigste van dergelijke apparaten zijn al bijna sinds de eeuwwisseling beschikbaar – en het is moeilijk te geloven dat het al 19 jaar geleden is! Heb je ooit overwogen hoe het classificatiesysteem stilletjes de prestaties van hoortoestellen beïnvloedt?
Hoewel er nog steeds enkele individuen zijn die hun hoortoestellen handmatig willen bedienen, geven de meeste mensen er de voorkeur aan om ze op te zetten en te vergeten, zodat de hoortoestellen zich automatisch kunnen aanpassen aan hun veranderende luisteromgevingen. Dat legt veel verantwoordelijkheid op de precisie van de classificatie waartoe dat apparaat in staat is.
Naarmate digitale hoortoestellen geavanceerder zijn geworden, is hun prestatie gestaag verbeterd. Maar ook de complexiteit van de onderliggende akoestische classificatieschema's die het allemaal mogelijk maken. Met de lancering van Indigo in 2005 introduceerde Unitron een nieuw type classificatiesysteem. Het was onze eerste classifier die getraind was met behulp van kunstmatige intelligentie om onderscheid te maken tussen vier verschillende akoestische scènes: rustig luisteren, spraak in lawaai, lawaai en muziek.
Met de introductie van onze conversationele classifier op het North-platform werden we zo zeker van ons vermogen om zeven verschillende luisteromgevingen correct te classificeren dat we de classifier-uitvoer gebruiken om Log It All aan te sturen, een primeur in de Unitron-industrie. Hoewel datalogging je vertelt wat het hoortoestel in de loop van de tijd doet, vertelt Log It All je hoeveel tijd de drager in elk van de zeven luisteromgevingen doorbrengt - en geeft je een overzicht van de luisterlifestyle van de drager, zodat je de ervaring van de drager in elke omgeving kunt individualiseren. Echter, om Log It All van waarde te laten zijn, moeten we er zeker van zijn dat de classifier deze luisteromgevingen nauwkeurig categoriseert.
Classificatie is nog belangrijker voor een goede gebruikerservaring. U kunt perfect parameters instellen voor elke luisteromgeving bij de eerste pasvorm, maar als de classifier die de automatische programma-omschakeling aanstuurt de akoestische omgeving verkeerd detecteert, zal dat allemaal niet uitmaken. Als de classifier bijvoorbeeld denkt dat de drager naar muziek luistert terwijl hij eigenlijk een gesprek voert in een stille omgeving, zal de prestatie van het hoortoestel ondermaats zijn, omdat het is geoptimaliseerd voor de verkeerde luisteromgeving.
Bijgevolg is een nauwkeurige classificatie een absoluut cruciaal onderdeel van succes met moderne hoortoestellen. Bij Unitron wilden we weten: hebben we het goed? Hebben we onze classifier getraind om de echte akoestische omgevingen waarin consumenten hun tijd doorbrengen nauwkeurig te detecteren?
Om onze vragen te beantwoorden, hebben we een benchmarkstudie uitgevoerd van onze conversationele classifier aan de University of South Florida met Dr. David Eddins en Dr. Erol Ozmeral.
Wat Classifiers doen:
Automatische classificatoren bemonsteren de huidige akoestische omgeving en genereren waarschijnlijkheden voor elk van de luisterbestemmingen die beschikbaar zijn in het automatische programma. Het hoortoestel schakelt over naar het luisterprogramma waarvoor de hoogste waarschijnlijkheid wordt gegenereerd. Het zal opnieuw schakelen wanneer de akoestische omgeving voldoende verandert zodat een andere luisteromgeving een hogere waarschijnlijkheid genereert.
Echter, niet alle classificatieschema's werken op dezelfde manier. Wat hen uniek maakt, is de filosofie van de ingenieurs die ze creëren. Het zijn deze filosofieën die hun keuzes bepalen over welke aspecten van een bepaalde akoestische omgeving het onderscheiden van alle anderen. Overweeg dit: twee fabrikanten' hoortoestellen kunnen aan dezelfde akoestische omgeving worden blootgesteld en deze anders classificeren. Waarom gebeurt dit? Het is omdat de ontwerpers van de twee systemen verschillende wegingen hebben toegekend aan de verschillende aspecten van die akoestische omgeving. Daarom maten de apparaten verschillende aspecten van de omgeving en namen ze verschillende beslissingen over de waarden van wat ze detecteerden. Zo kunnen ze verschillende conclusies trekken over de akoestische omgeving zelf.
Overweeg bijvoorbeeld deze representatieve benaderingen voor akoestische classificatie in hoortoestellen:
- (Kates, 1995) beschreef een systeem gebaseerd op clusteranalyse van envelopmodulatie en spectrale kenmerken om achtergrondgeluiden in elf klassen te classificeren: appartement, geroezemoes, diner, vaat, gaussisch, printer, verkeer, typen, mannelijke spreker, sirene en ventilatie.
- (Nordqvist & Leijon, 2004) gebruikten verborgen Markov-modellen om een robuust classificatiesysteem te ontwikkelen voor hoortoestellen met drie klassen: spraak in verkeerslawaai, spraak in geroezemoes en schone spraak.
- (Büchler, Allegro, Launer, & Dillier, 2005) classificeerde zuivere spraak, spraak in lawaai, lawaai en muziek met behulp van meerdere benaderingen. De auteurs legden veel soorten kenmerkextractie uit en vergeleken vervolgens zes verschillende classificatoren van lage tot matige complexiteit, vereist voor HA-gebruik.
- (Lamarche, Giguere, Gueaieb, Aboulnasr, & Othman, 2010) testten twee systemen: Minimumafstand en Bayesiaanse classificaties. In elk geval kan de classifier zich aanpassen aan de unieke omgevingen van de luisteraars en zichzelf dienovereenkomstig afstemmen. Ze kozen onderscheidende kenmerken die goed zijn voor het onderscheiden van Spraak-, Ruis- en Muziekomgevingen, waaronder Diepte van amplitudemodulaties, Modulatiefrequentiebereiken (0 – 4 Hz & 4 – 16 Hz), en Tijdelijke variatie van de onmiddellijke frequentie. Ze ontdekten dat beide methoden goed werkten. Maar ze hadden de neiging om klassen anders samen te voegen bij het terugbrengen van drie naar twee klassen.
Hoewel deze lijst niet uitputtend is, toont het veel van de benaderingen die beschikbaar zijn voor ingenieurs en wetenschappers die deze algoritmen ontwikkelen. Hoewel de filosofieën van hoortoestelbedrijven eigendom zijn, is het nog steeds mogelijk om deze schema's met elkaar te vergelijken en met een gouden standaard om te evalueren wat verschillende systemen te bieden hebben. Daartoe hebben we een benchmarkbenadering ontwikkeld op basis van het repliceren van echte luisteromgevingen in een gecontroleerde en herhaalbare setting. De aanpak en enkele van de resultaten zullen in dit document worden beschreven.
De benchmarkingbenadering:
We kozen ervoor om de classificaties te benchmarken door twee soorten vergelijkingen toe te passen. Eerst vergeleken we alle hoortoestelclassificaties met een menselijke gouden standaard. Ten tweede vergeleken we de resultaten van de classifier voor gehoorinstrumenten van vijf fabrikanten met elkaar. Beide benaderingen bieden nuttige inzichten.
De locatie
We voerden alle metingen uit in het Auditory & Speech Sciences Laboratory aan de University of South Florida. De geluidskamer wordt getoond in Figuur 1.

Figuur 1
De stoel in het midden van de kamer is omgeven door een reeks van 64 onafhankelijk aangedreven luidsprekers op oorhoogte. Hoewel de kamer een traditionele geluiddichte testkamer is, kunnen plexiglazen panelen aan de muren en het plafond worden gemonteerd om een natuurlijker galmende omgeving te creëren. Menselijke deelnemers zitten in de stoel in het midden van de kamer terwijl ze luisteromgevingen evalueren. We verkregen gehoorinstrumentgegevens in sets van drie apparaten tegelijk met behulp van een Klangfinder antropomorf systeem (Figuur 2).
Door de menselijke deelnemers in het midden van de kamer te vervangen door de Klangfinder, was het mogelijk om alle testomstandigheden voor alle proefpersonen en alle hoortoestellen op één locatie te herhalen.

Figuur 2
Het Geluidsparkour
We begonnen de meetoefening door een geluidsparkour te creëren – een soort akoestisch hindernisparcours om de classificatoren op de proef te stellen. We definieerden de parkour in meerdere dimensies, zoals weergegeven langs de kop en de linkerkolom van Tabel 1. Elke rij van Tabel 1 beschrijft de samenstelling van een enkel geluidsbestand dat twee minuten duurt en een specifieke luisteromgeving vertegenwoordigt. Deze iteratie van de parkour bevat 26 luisteromgevingen (geluidsbestanden). De eenvoudigste luisteromgeving wordt stille luisteromgeving genoemd (in de bovenste rij). Er is geen spraak, alleen het zachte geluid van een ventilator die gestaag draait met een algeheel niveau van 40 dB SPL. Er is bijna geen modulatie en geen temporele of spectrale contrasten – slechts een zacht, constant geluid.
Naarmate je verder naar beneden in de tabel gaat, worden de luisteromgevingen complexer. Bijvoorbeeld, in de linkerkolom zie je dat we meer sprekers en verschillende soorten achtergrondgeluid hebben toegevoegd. We experimenteerden ook met verschillende niveaus van muziek en achtergrondgeluid gecombineerd met spraak in de zeer complexe omgevingen.
Er is ook een directionele component aan de spraak-, ruis- en muziekelementen. Naarmate er meer luidsprekers worden toegevoegd, wordt hun oriëntatie ten opzichte van de voorkant van de hoortoestellen bijgewerkt om weer te geven waar een luidspreker normaal zou staan of zitten in die omgeving. Deze stap omvat elke impact van directionele verwerking. Let bijvoorbeeld op de oriëntatie van de luidsprekers – links, rechts en voor – in de metro-omgeving. Deze "praterverdeling" is wat je zou ervaren op een metroperron in de Londense metro wanneer je tussen twee metgezellen zit met een andere persoon voor je die een gesprek voert. De richtingscomponent wordt ook gebruikt voor het geluid en de muziek in de geluidsbestanden. Meerdere iteraties van de geluidsparkour zijn gebruikt, waarvan Tabel 1 (download Tabel 1) een representatief voorbeeld is.
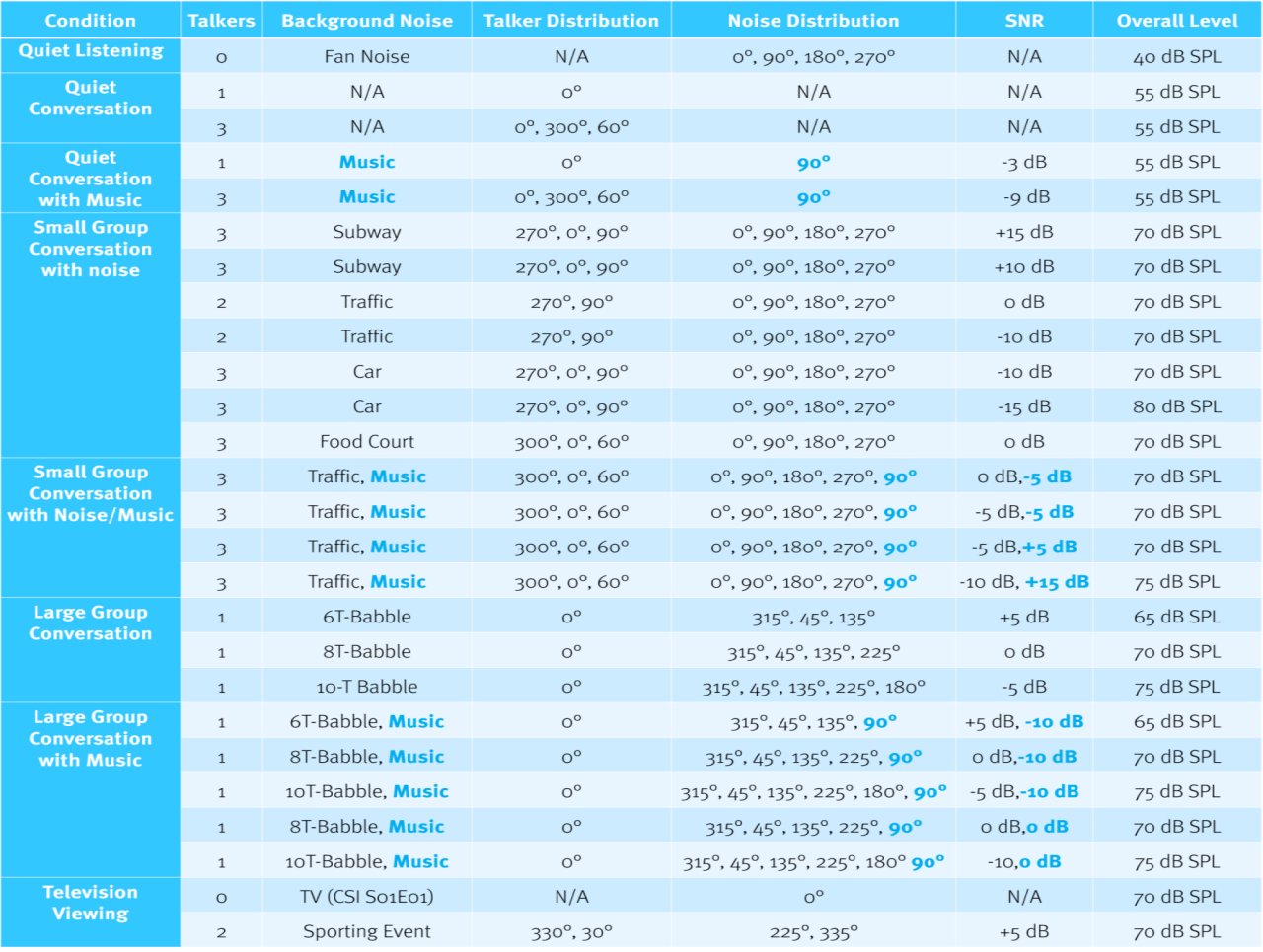
Tabel 1.
Elk geluidsbestand werd acht uur lang continu afgespeeld voor elke set hoortoestellen in de Klangfinder. Er was geen directe manier om de classifier-kansen van de meeste apparaten af te lezen. In plaats daarvan vertrouwden we op de dataloggingresultaten van acht uur van een enkel bestand om te bepalen hoe de classifier van elke fabrikant die specifieke luisteromgeving logde. Aangezien de datalogging van de tijd die in een bepaalde luisteromgeving wordt doorgebracht hoogstwaarschijnlijk wordt aangedreven door classifier-kansen in de loop van de tijd, was het herhalen van een enkel geluidsbestand gedurende acht uur/sessie de meest logische manier om stabiele classifier-uitkomsten te verkrijgen.
Hoe zien de daadwerkelijke classificatieresultaten eruit?
Voordat we naar de resultaten kijken die indirect zijn verkregen van gehoorinstrumenten van vijf fabrikanten met behulp van datalogging-uitvoer, is het leerzaam om naar meer gedetailleerde resultaten van Unitron-gehoorinstrumenten te kijken. Het is mogelijk voor Drs. Eddins en Ozmeral om de waarschijnlijkheden van de classifier direct meerdere keren per seconde uit ons hoortoestel af te lezen terwijl ze worden gegenereerd. Figuur 3 en 4 tonen de werkelijke classifier-kansen zoals bepaald door een paar Unitron-hoortoestellen met behulp van deze benadering. Het eerste geval, Figuur 3, toont 60 seconden aan classifier-kansen voor twee zeer eenvoudige luisteromgevingen.

Figuur 3
Bovenaan Figuur 3 kunnen we 60 seconden van de originele weergave zien. De eerste helft van deze figuur toont de laatste 30 seconden van de WAV-bestandsopname van de zachte ventilatoromgeving (de bovenste rij van Tabel 1). De tweede helft toont de eerste 30 seconden van de twee minuten durende opname van het stille gesprek WAV-bestand met een enkele spreker (tweede rij van Tabel 1). Deze eenvoudige luisteromgevingen demonstreren hoe de classifier waarschijnlijkheden genereert die bijna uitsluitend een enkele akoestische luisteromgeving vertegenwoordigen.
Het onderste midden van de figuur is gesynchroniseerd met de opnamen en toont de verdeling van waarschijnlijkheden voor elk van de zeven mogelijke luisteromgevingen in de Unitron-classificator. De eerste 30 seconden is er een kans van 100% dat dit een stille luisteromgeving is. Aangezien het een opname is van een zachte ventilator gemeten op slechts 40 dB SPL in een geluiddichte kamer, is die classificatie correct. Het hoortoestel zou deze 30 seconden doorbrengen in de stille luisteromgeving van SoundNav.
Na 30 seconden schakelt de opname abrupt van de zachte ventilator bij 40 dB SPL naar een enkele spreker bij 55 dB SPL. Van 30 seconden tot ongeveer 37 seconden zijn de classifier-kansen in transitie. Merk op hoe de waarschijnlijkheid van spraak in stilte onmiddellijk begint te stijgen naarmate de waarschijnlijkheid van stil luisteren daalt. De twee waarschijnlijkheden snijden elkaar op ongeveer 35 seconden. In deze overgangszone schakelt SoundNav het hoortoestel van de stille luisteromgeving naar de spraak in stille luisteromgeving. De classifier detecteert de verandering eigenlijk bijna onmiddellijk, maar onze ontwikkelaars hebben bewust besloten om het apparaat niet te snel te laten reageren op elke kleine verandering in de akoestische omgeving. Snelle veranderingen kunnen leiden tot verminderde geluidskwaliteit in dynamische luisteromgevingen terwijl SoundNav probeert bij te blijven met alle omgevingsfluctuaties.
Tegen 40 seconden en voor de laatste 20 seconden van de opname is de kans op een toespraak in een stille luisteromgeving bijna 100%.
De twee verticale balken aan de linker- en rechterkant van het sectie van de classifierverhoudingen tonen de verhouding van de tijd die in elk van de zeven mogelijke luisteromgevingen is doorgebracht voor het paar van twee minuten durende WAV-bestanden. De rode balk aan de linkerkant is de volledige twee minuten van het zachte ventilator WAV-bestand, en de rode en blauwe balk aan de rechterkant tonen de tijdsverdeling in elk van de zeven luisteromgevingen tijdens de twee minuten van de spraak in stille WAV-bestand. Het lichte rode gedeelte vertegenwoordigt de overgangstijd aan het begin van de toespraak in stille opname.
Figuur 4 is een voorbeeld van wat er gebeurt in een complexere luisteromgeving.

Figuur 4.
Hier kunnen we de impact zien op de waarschijnlijkheden van twee veel complexere luisteromgevingen. In beide gevallen rijdt de luisteraar in de auto samen met drie sprekers. Aan de linkerkant (de eerste 30 seconden) is de auto veel stiller met een algemeen niveau van ongeveer 70 dB en een -10 dB SNR. De algehele niveaus zijn veel moeilijker in de tweede 30 seconden bij een algemeen signaalniveau van 80 dB met -15 dB SNR. Deze niveaus kunnen eruitzien als bijna onmogelijke SNR's voor een hoortoestelgebruiker, maar het autogeluid is kenmerkend doordat bijna alle energie in de zeer lage frequenties zit (onder 1000 Hz). Als zodanig zien de SNR's er extreem uit, maar bijna alle hoge frequentie spraak is duidelijk hoorbaar in beide WAV-bestanden.
Naarmate de auto van snelheid verandert en de sprekers beginnen en stoppen, variëren de classificatorwaarschijnlijkheden sterk in een mix van drie verschillende luisteromgevingen. Tijdens de zachtere eerste 30 seconden is de hoogste waarschijnlijkheid die van een gesprek in een kleine groep, gemiddeld 50% tot 60%. Zoals je zou verwachten, wordt ook gesprek in lawaai gedetecteerd, variërend van 0% tot 50%. Gesprek in een grote groep heeft een kleinere maar nog steeds merkbare kans die rond de 15% tot 20% zweeft. Zodra het algehele niveau stijgt en de SNR slechter wordt, wordt het geluid van het autolawaai overheersend. Naarmate de auto versnelt, verschuiven de classifier-kansen sterk naar het gesprek in een lawaaiige omgeving en het gesprek in een kleine groep daalt tot onder de 20%.
Neem een moment om na te denken over deze twee voorbeelden. De eerste is makkelijk. Na het vergelijken van hoortoestellen van veel fabrikanten, is het duidelijk dat ze allemaal op vergelijkbare wijze zouden reageren in beide luisteromgevingen die in Figuur 3 worden getoond.
Maar wat te zeggen over de twee omgevingen in Figuur 4? Dit is waar filosofie een rol speelt. Er gebeurt veel in deze luisteromgevingen en ontwikkelaars moeten enkele beslissingen nemen over wat te doen. Bijvoorbeeld, wat is belangrijker: het elimineren van het autogeluid of het verbeteren van de spraak? Op welk punt is het algehele geluidsniveau te luid en niet de moeite waard om je zorgen te maken over de spraak? Is die beslissing gebaseerd op het algehele niveau of SNR? Het geluidsparkour is ontworpen om al die mogelijkheden te bekijken om te achterhalen welke relevante keuzes zijn gemaakt.
De gouden standaard:
Tabel 1 bevat geluidsbestanden die verschillende algemene luisteromgevingen vertegenwoordigen die een drager van een hoortoestel in het echte leven kan tegenkomen. Hoe wisten we dat de bestanden de aangewezen luisteromgevingen nauwkeurig weergaven? We hadden 17 normaal horende luisteraars die voor ons bepaalden welke luisteromgevingen volgens hen het beste werden vertegenwoordigd door elk geluidsbestand. (Meerdere antwoorden waren acceptabel.) De geluidsbestanden werden in willekeurige volgorde afgespeeld voor onze luisteraars. Ze hoorden elk geluidsbestand drie keer, en ze beschreven de omgeving voor elke iteratie van elk geluidsbestand. We hebben vervolgens al hun antwoorden verzameld om te vergelijken met de gehoorinstrumentclassificaties.
In Tabel 2 zien we hoe de beschrijvingen van onze menselijke luisteraars vergeleken met de zeven luisteromgevingen in onze classifier:

Tabel 2
Hoewel er enige overlap was in specifieke terminologie, waren er interessante verschillen in de interpretatie van wat die namen betekenden. Er waren drie namen voor luisteromgevingen die zowel door de luisteraars als de classifier werden gebruikt: "stil", "lawaai" en "muziek". De interpretatie van elke term was echter vaak heel specifiek. "Stil" werd zeer zelden gebruikt door onze luisteraars en overschreed zelden 3% voor elke luisteromgeving. Bijvoorbeeld, het geluidsbestand van de ventilator bovenaan Tabel 1 kreeg een 100% kans op "stil" door onze classifier aangezien het algehele niveau slechts 40 dB SPL was, maar onze luisteraars noemden het "lawaai" 92% van de tijd. Interessant genoeg gaven onze luisteraars ons slechts in twee andere luisteromgevingen een kans van "ruis" boven de 27%, die beide behoorlijk luid waren. De echt lawaaierige geluidsbestanden bevatten allemaal spraak en kregen daarom de hoogste waarschijnlijkheden van "spraak in lawaai" door onze luisteraars. Hetzelfde gold voor de classifier, behalve dat het een onderscheid maakte op basis van het type geluid, ofwel meerdere achtergrondsprekers of motorgeluiden zoals treinen, auto's of verkeer. Noch de luisteraars noch de classifier detecteerden "muziek" erg vaak, en alleen wanneer het veel luider was dan alles eromheen. Maar de luisteraars boden een aparte categorie van "spraak in muziek" gemengd met "spraak in lawaai" in zeven omgevingen waar de classifier een "grote groep" detecteerde (wat ze waren, maar de classifier negeerde de muziek ten gunste van het optimaliseren van spraak).
De belangrijkste verschillen tussen de luisteraars en de classifier waren niet zozeer dat ze verschillende dingen detecteerden, maar dat ze verschillende aspecten van de geluidsbestanden prioriteerden of in sommige gevallen iets preciezere onderscheidingen maakten. Men zou bijvoorbeeld gemakkelijk kunnen beweren dat een zachte ventilator bij 40 dB SPL zowel stil als een geluid is. Beide zijn correcte interpretaties van dezelfde luisteromgeving.
De multiproductvergelijking:
De volgende resultaten laten zien hoe premiumproducten van vijf fabrikanten, waaronder Unitron, verschillende luisteromgevingen classificeren ten opzichte van onze jonge normaal horende luisteraars. Deze oefening gaat niet over wie gelijk heeft of wie ongelijk heeft – het is eerder een kans om te zien hoe verschillende classificatoren zich verhouden. De resultaten toonden aan dat sommige hoortoestellen beter zijn in classificatie dan andere, en de verschillende filosofieën van bedrijven neigen zich te onthullen.
Laten we opnieuw beginnen met een eenvoudig voorbeeld. Figuur 5 toont hoe de jonge normale luisteraars en de vijf hoortoestellen een enkele mannelijke spreker van voren bij 55 dB SPL classificeerden.

Figuur 5
Verschillende fabrikanten hebben verschillende classificatieschema's die verschillende namen gebruiken voor de luisteromgevingen die ze classificeren. Aan de hand van hun beschrijvingen van waar elke luisterbestemming voor bedoeld was, hebben we de titels in vier hoofdcategorieën gegroepeerd: stilte, spraak in lawaai, lawaai en muziek (zoals weergegeven in de legenda van Figuur 5). Deze vier algemene categorieën komen voor in alle hoortoestellen die we hebben getest onder de ene of andere naam, maar we gebruikten de generieke namen in onze resultaten om de anonimiteit van de fabrikanten en betrokken hoortoestellen te behouden. Onze normale luisteraars classificeerden dit geluidsbestand ongeveer 98% van de tijd als rustig luisteren. Alle vijf hoortoestellen deden hetzelfde.
Figuur 6 is iets complexer dan Figuur 5. Er is opnieuw een enkele spreker direct voor de luisteraar, maar het algehele niveau van het geluidsbestand is nu 80 dB SPL met een nominale SNR van 0 dB. Het achtergrondgeluid is een metrotrein in de Londense metro, en de niveaus varieerden naarmate treinen aankwamen en vertrokken.

Figuur 6
Onze normale luisteraars classificeerden dit bestand ongeveer 83% van de tijd als spraak in ruis. Ze zeiden ook dat het 4% van de tijd lawaai was en 10% van de tijd stil. Rekening houdend met de niveauverschillen terwijl treinen kwamen en gingen, is het eerlijk om te zeggen dat Unitron en Concurrent D het dichtst bij kwamen wat de jonge normaal horende luisteraars ons vertelden. Concurrent A was niet ver achter, echter, Concurrenten B & C waren heel anders.
Dit is waar de verschillen in filosofie voor het eerst worden blootgelegd. Als we naar Concurrent B kijken, classificeerde dat instrument de omgeving als slechts ruis ongeveer 50% van de tijd. Het is duidelijk dat onze normale luisteraars spraak in lawaai vrij consistent rapporteren. Daarom moet de SNR meestal redelijk zijn. Echter, bij 80 dB is het algehele niveau vrij hoog. Dus, we concluderen dat Concurrent B een filosofie heeft die in dit geval gevoeliger is voor het algehele niveau dan voor de SNR, net als de andere vier geteste hoortoestellen.
De achtergrond wordt nog complexer in Figuur 7. Hier evalueerden de luisteraars een enkele spreker van voren in een achtergrond van een food court in het winkelcentrum rond lunchtijd. Het algehele niveau was iets lager op 70 dB SPL bij een 0 dB SNR. Dit is een complexe achtergrond van tientallen mensen die tegelijkertijd veel gesprekken voeren, evenals het geluid van de keukens die eten serveren en mensen die voorbij lopen.

Figuur 7
In dit geval rapporteren onze normaal horende luisteraars ongeveer 47% spraak in lawaai en ongeveer 50% alleen lawaai. De andere 3% was muziek. Deze keer variëren de resultaten van de classifier sterk tussen fabrikanten. Hoewel alle classificaties een combinatie van spraak in lawaai en lawaai boden, waren de percentages voor Concurrenten A & C volledig het tegenovergestelde van die voor Concurrenten B & D.
Dit kan het perfecte voorbeeld zijn van filosofische verschillen in wat Unitron Hearing Scientist, Leonard Cornelisse "het opgavepunt" noemt. Hij definieert het opgevenpunt als het signaalniveau en/of SNR waar de drager van het hoortoestel "het opgeeft" om de spraak te volgen omdat de situatie te moeilijk is geworden. Onder het opgavepunt zal de luisteraar proberen te volgen wat er wordt gezegd en dit rapporteren als een spraak-in-ruis omgeving, waarbij verwacht wordt dat het hoortoestel de spraakhelderheid benadrukt. Maar zodra het opgavepunt is overschreden, meldt de luisteraar dat het te moeilijk is om de spraak te volgen of te luid om comfortabel te luisteren, en ze willen dat het hoortoestel comfort boven duidelijkheid benadrukt. Elke classifier is gebouwd om die beslissing op een bepaald moment te nemen, en het is een puur akoestisch gedreven beslissing. (Tenzij de luisteraar overschakelt naar een handmatig programma om het te negeren.)
De eerste conclusie uit Figuur 7 is dat Concurrenten A & C een hoger opgavepunt aannemen dan Concurrenten B & D. Zowel Unitron als de normale luisteraars hebben aangegeven dat deze omgeving vrij goed op de opgavepuntlijn ligt met een bijna 50/50 verdeling tussen spraak in lawaai en lawaai. Dit is misschien wel het meest opvallende voorbeeld van filosofie die de prestaties beïnvloedt. Aangezien het opgavepunt voor verschillende slechthorenden vaak sterk varieert, wie kan zeggen welk van deze bedrijven het absoluut goed zal doen voor een bepaalde luisteraar?
Het laatste voorbeeld is voor het luisteren naar muziek. In Figuur 8 zien we de resultaten voor muziek die alleen wordt afgespeeld (zonder andere achtergrondgeluiden) op een niveau van 65 dB SPL. Dit is geen hoog niveau om naar muziek te luisteren en reproduceert geen live optreden. Het is eerder dichter bij het niveau waarop een drager van een hoortoestel naar muziek kan luisteren terwijl hij kookt of een boek leest, maar iets luider dan achtergrondmuziek.

Figuur 8
In dit geval gaven de normale luisteraars, Unitron, Concurrent A en Concurrent C allemaal aan dat dit in wezen een pure muziek luisteromgeving was. Concurrenten B & D classificeerden het respectievelijk in 33% en 20% van de gevallen anders. De meest voorkomende misclassificatie hierbij was voor spraak in lawaai, en dit is het enige geval waar een duidelijke en onverdedigbare misser plaatsvond. Muziek voor spraak aanzien in lawaai komt neer op het instellen van een hoortoestel voor precies het tegenovergestelde type prestatie dat je zou verkiezen. Het is algemeen geaccepteerd om een muziekomgeving in te stellen voor breedband licht verwerkt reproductie. Maar spraak in lawaai krijgt meestal een flinke dosis richtmicrofoons en ruisonderdrukking die, onder andere, is ontworpen om lage frequentie versterking te verminderen. Eerlijk gezegd was zo'n misser niet gebruikelijk voor de vijf classificatoren.
Samenvatting
Geluidsscèneclassificatie van hoortoestellen is een onderwerp dat weinig aandacht krijgt. Toch is het een van de belangrijkste componenten van de architectuur van het instrument. Stilletjes op de achtergrond werkend, nemen classifiers alle beslissingen over welke sets van verwerkingsparameters het meest geldig zijn in een bepaalde luisteromgeving, en hebben ze een grote invloed op hoe een drager hoort.
Classificatiebeslissingen zijn net zozeer gebaseerd op filosofie als op akoestiek. Als zodanig zijn niet alle classificatoren in alle situaties gelijk. Meestal, vooral in eenvoudige luistersituaties, zullen bijna alle top gehoorapparaten convergeren naar zeer consistente resultaten die overeenkomen met hoe een normaal horende luisteraar de omgeving zou classificeren. Maar zodra de luisteromgeving complexer wordt, worden de verschillen in filosofie en soms prestaties duidelijk.
Met SoundNav, een classifier getraind met behulp van kunstmatige intelligentie, zijn de resultaten van Unitron zeer consistent met die van onze jonge normaal horende luisteraars.
Dankwoord
Ik wil graag dr. Ozmeral en dr. Eddins bedanken voor hun bijdrage. Zij werkten nauw met ons samen om het geluidsparcours te ontwerpen en gegevens te verzamelen in hun lab op de University of South Florida.
Referenties:
Büchler, M., Allegro, S., Launer, S., & Dillier, S. (2005). Geluidsclassificatie in hoortoestellen geïnspireerd door auditieve scène-analyse.EURASIP Journal on Applied Signal Processing, 18, 2991–3002.
Kates, J. M. (1995). Classificatie van achtergrondgeluiden voor hoortoesteltoepassingen.J Acoust Soc Am, 97(1), 461-470.
Lamarche, L., Giguere, C., Gueaieb, W., Aboulnasr, T., & Othman, H. (2010). Adaptief omgevingsclassificatiesysteem voor hoortoestellen.J Acoust Soc Am, 127(5), 3124-3135. doi:10.1121/1.3365301
Nordqvist, P., & Leijon, A. (2004). Een efficiënte robuuste geluidsclassificatie-algoritme voor hoortoestellen.J Acoust Soc Am, 115(6), 3033-3041.
Misschien ook interessant
